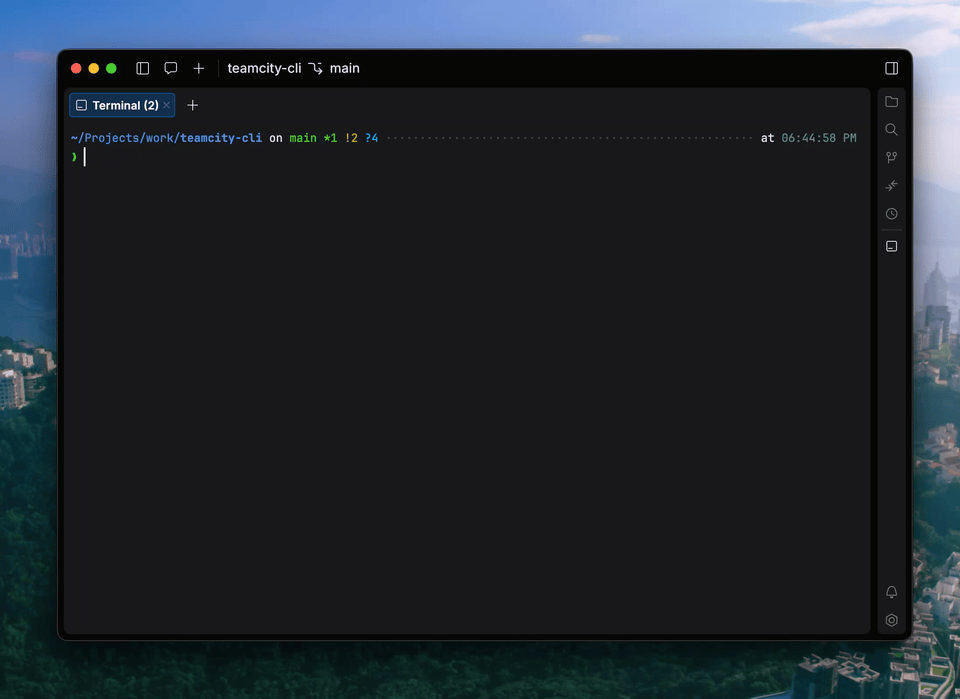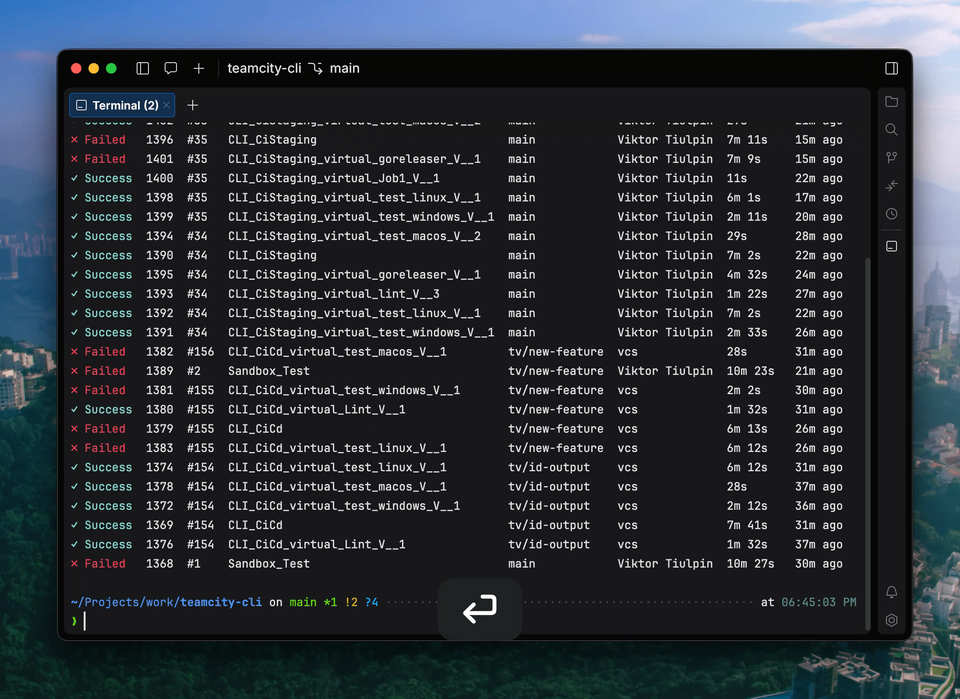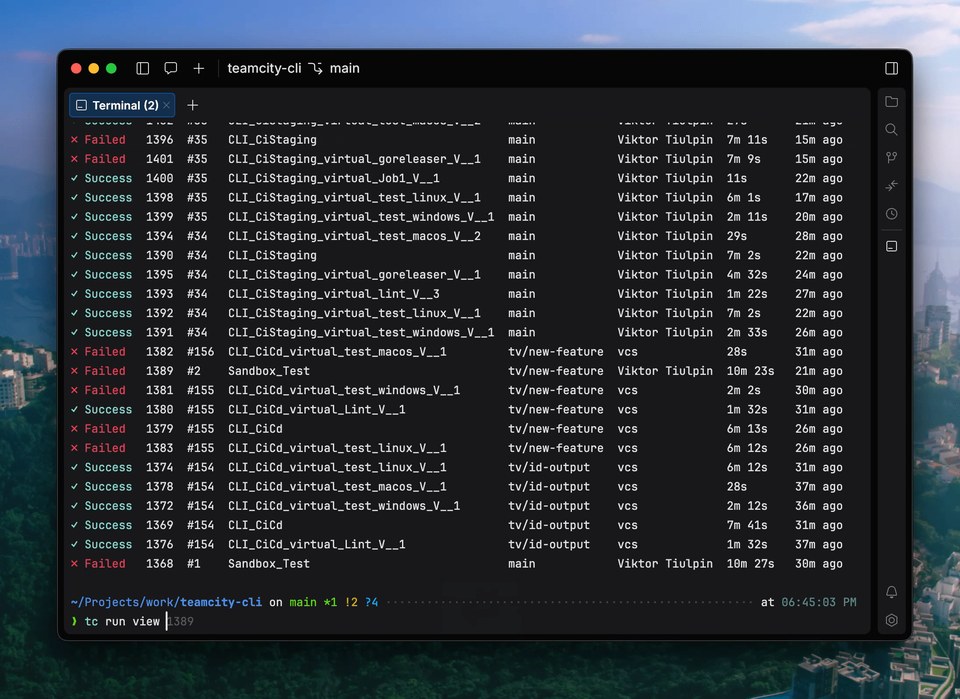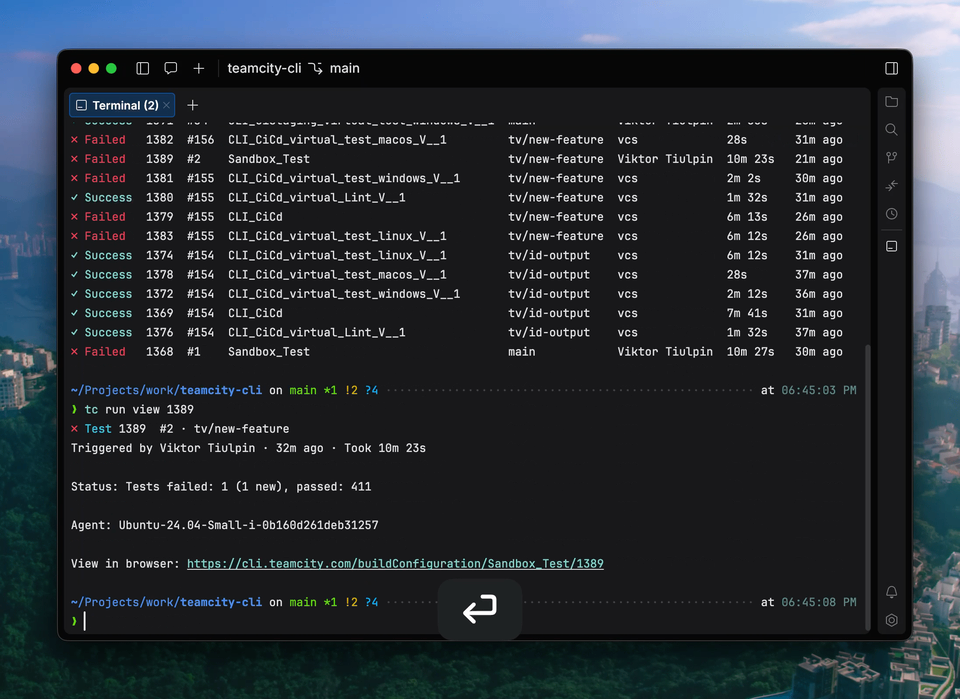
Extension marketplaces have quietly become one of the most strategic control points in modern developer tooling.
As editors and IDEs evolve into platforms, and as AI systems increasingly orchestrate development workflows, the registry behind those extensions is no longer a secondary service. It is infrastructure.
Over the past weeks, we (the Eclipse Foundation) have shared several updates on how we are strengthening that infrastructure.
Christopher Guindon outlined how we are introducing proactive pre publish security checks to improve trust in the Open VSX Registry and reduce supply chain risk.
He then explained why structured rate limiting is necessary to ensure the Registry can scale responsibly as AI driven automation increases traffic and operational pressure.
Denis Roy has also detailed how we are investing in infrastructure reliability and security to reinforce the operational backbone of the service.
Together, these posts explain how we are strengthening and scaling Open VSX as critical shared infrastructure.
In this post, I would like to step back and focus on a different dimension: why Open VSX matters from a software sovereignty perspective.
The structural challenge Open VSX addresses
Modern editors and IDEs are no longer standalone tools. They are platforms. Their extension ecosystems define capabilities, integrations, and increasingly AI behaviour.
- Control over the extension marketplace determines:
- who can publish and distribute extensions
- under what conditions
- which APIs and integrations are viable
- how AI driven workflows are assembled
- whether competing platforms can operate independently
For many vendors, compatibility with the Visual Studio Code extensibility model has become essential. It is now a de facto standard across modern developer tools, including many AI native environments.
However, the Microsoft Marketplace is intended for Microsoft’s own distributions. VS Code forks, downstream distributions, and tools that are not Microsoft products cannot rely on it as their extension marketplace.
This creates a gap: maintaining ecosystem compatibility without marketplace dependency.
Open VSX was created to address this gap with a vendor neutral, open source governed registry.
A neutral, open source governed foundation
- Eclipse Open VSX is an open source project: https://github.com/eclipse/openvsx
- The Open VSX Registry, is the hosted instance operated by the Eclipse Foundation: https://open-vsx.org/
The distinction matters: the project evolves in the open, while the service is governed by a non profit foundation, with strategic direction coordinated through the Open VSX Working Group.

The Eclipse Foundation operates as a global community, with its legal seat in Brussels, ensuring neutrality, transparency, and long-term stewardship.
In practice:
- no single vendor controls marketplace policy,
- decisions are not dictated by a commercial competitor,
- the registry software is open source,
- participation is structured and transparent.
Open VSX provides neutral ground for extension distribution and discovery.
Why sovereignty has become central in the AI era
AI has significantly increased the strategic importance of extension ecosystems.
AI coding platforms depend on extensible components such as:
- Language server
- static analysis engines
- debug adapter
- framework integrations
- code generation and transformation tools
Many AI development tools, whether VS Code based or independent, rely on Open VSX as their extension distribution layer. Sometimes this is driven by licensing constraints, sometimes by architectural choice to avoid dependency on a proprietary marketplace.
As AI agents orchestrate workflows across tools and environments, extension registries become dependency hubs in automated pipelines.
If that layer is controlled by a single commercial actor, ecosystem participants inherit platform risk.
Open VSX mitigates that risk by providing a neutral alternative.
Software sovereignty in concrete terms
Sovereignty in developer tooling is operational, not abstract.
For tool vendors:
- ability to distribute extensions without competitor approval
- protection from unilateral policy changes
- transparent governance
- option to mirror, federate, or self host
For enterprises and public sector organisations:
- infrastructure governed by a neutral non profit foundation
- clear accountability and transparency
- reduced exposure to proprietary lock in
- alignment with regulatory and regional requirements
This also gives context to the operational work described earlier. Security, rate limiting, and infrastructure investment are not isolated improvements. They are required to sustain a sovereign, neutral ecosystem at scale.
European strategy, global competition, and open infrastructure
Software sovereignty is no longer a niche concern. It is increasingly central in policy and industry strategy, particularly in Europe.
As Europe evaluates its position in the context of significant US capital investment and large scale AI initiatives in China, the question is not only how much to invest, but where.
Digital sovereignty begins at infrastructure layers that shape ecosystems. Extension registries are one of those layers.
If Europe aims to foster competitive AI driven developer tooling, investing only in applications is insufficient. The underlying control points must remain open, interoperable, and neutral.
Open VSX represents one such control point.
It is global infrastructure, governed under a European legal framework, and open to participation from vendors and contributors worldwide. This combination, global collaboration with neutral governance, provides a practical model for sustaining open digital infrastructure.
Open alternatives that combine compatibility and independence
Sovereignty does not require fragmentation. It requires credible alternatives.
Open VSX provides compatibility with the dominant extension ecosystem while preserving independence from proprietary marketplace control.
Projects such as Eclipse Theia AI demonstrate that it is possible to build AI enabled developer experiences on fully open foundations.
Together, Theia AI and Open VSX offer:
- compatibility with the dominant extension ecosystem
- a modern, extensible, AI capable user experience
- open source implementation across the stack
- governance under a neutral foundation
This combination differs fundamentally from proprietary platforms or single vendor controlled open source projects. Governance matters as much as the code.
Open source alone is not sufficient if strategic control remains centralised. Neutral governance and community participation are essential to long term sovereignty.
Preserving architectural independence
The operational work described throughout this series, security hardening, responsible scaling, infrastructure investment, reflects the fact that Open VSX has become foundational infrastructure.
But the deeper objective is architectural independence.
As AI reshapes developer tooling and global competition intensifies, maintaining neutral, open source governed infrastructure layers becomes strategically important for vendors, enterprises, and public institutions.
Open VSX is not just an alternative registry. It is part of a broader effort to keep developer tooling open, interoperable, and governed in the public interest.
That is why it matters.
Thomas Froment