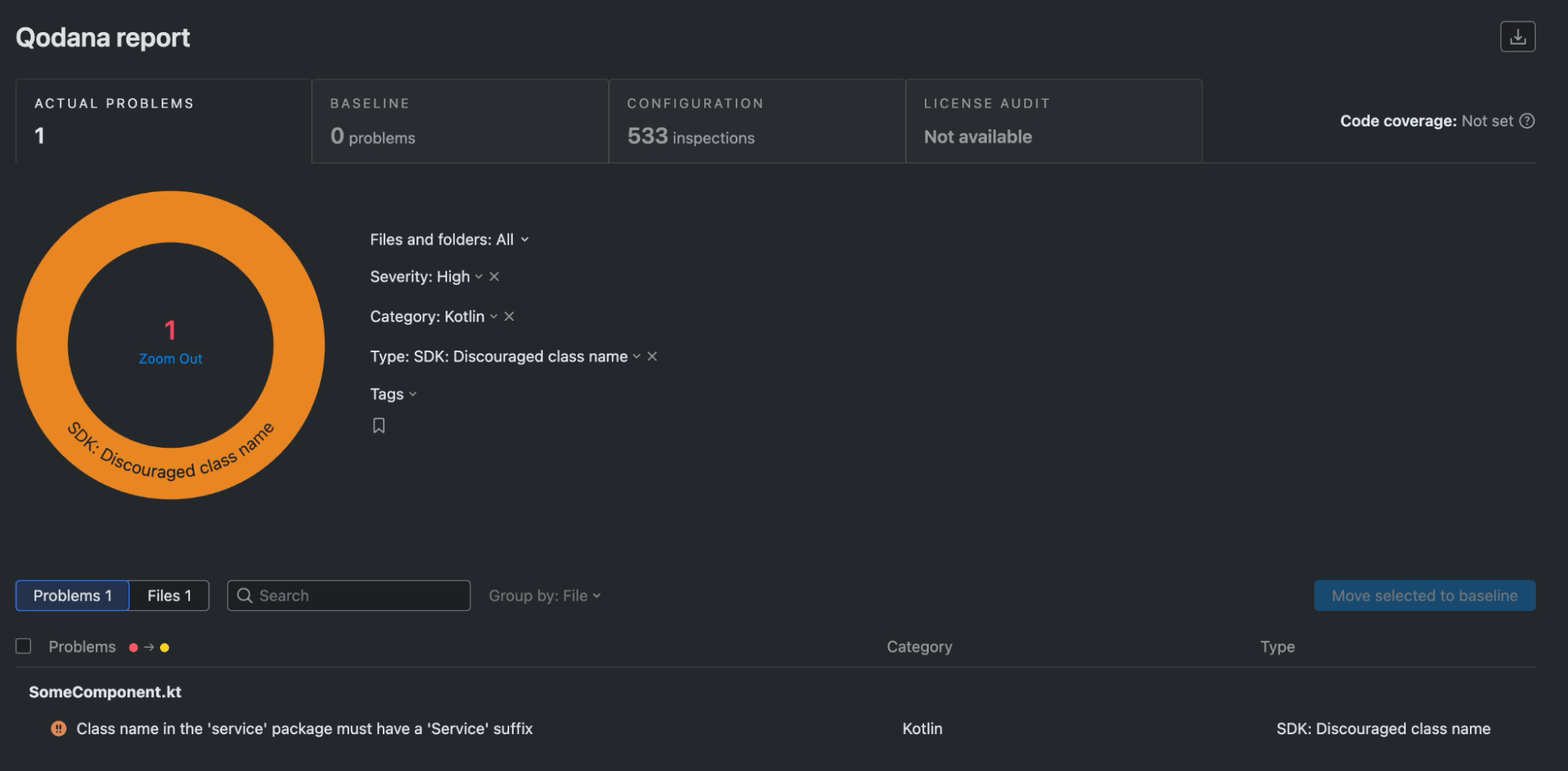
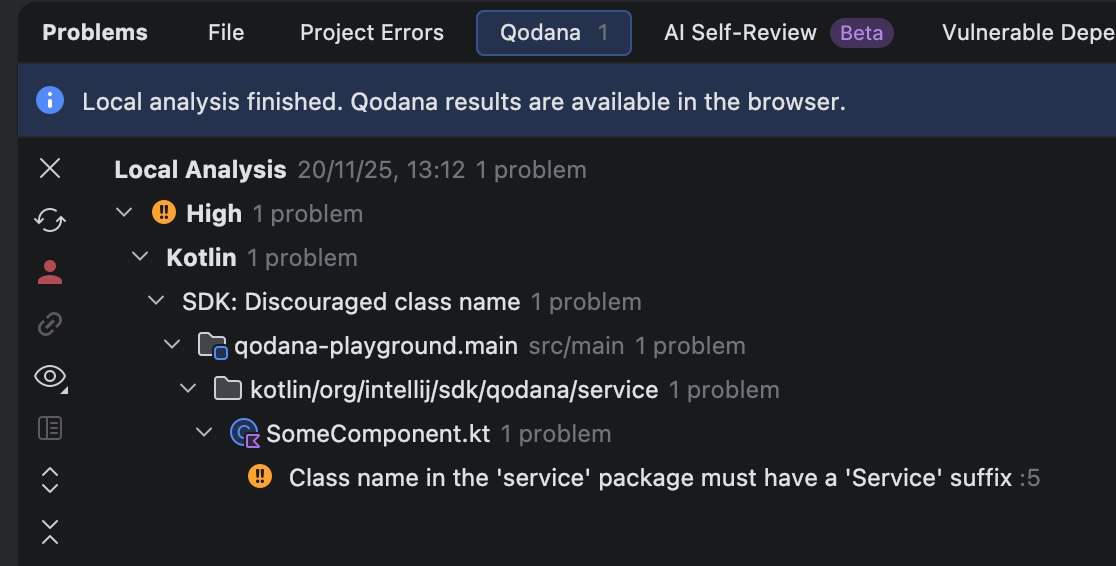
AI agents are being shipped to production faster than most integration layers were designed to handle. When workflows start breaking, it is usually not the model that is causing the trouble. It is authentication edge cases, permission boundaries, API limits, or long-running automations that quietly fail.
Platforms like Workato still appear early in evaluations, but teams are increasingly testing alternatives as systems become more API-driven and agent-initiated. By 2026, integrations are expected to behave like core infrastructure rather than background tooling.
This article looks at six Workato alternatives teams are actively using in 2026. The focus is on how these platforms behave in real environments, what they support well, and where trade-offs arise as workflows move beyond simple automations.
Before diving deeper, here is a quick TL;DR of the platforms worth considering.
TL;DR
If you want the quick takeaway, these are the Workato alternatives teams are actively evaluating in 2026 👇
-
Composio: Designed for AI agents running in production, with a large tool ecosystem, runtime execution, on-prem deployment, and MCP-native support.
-
Tray.ai: A good fit for complex, predefined enterprise workflows that need deep API orchestration.
-
Zapier: Optimized for quick, lightweight automations across common SaaS tools.
-
Make.com: Best for visually modeling complex, predefined workflows with branching, loops, and data transformation, especially for ops and business teams.
-
n8n: Ideal for teams that want full control through open-source, self-hosted automation with custom logic and deep API access.
Why a Workato Alternative Makes Sense in 2026
Integration platforms now sit directly on the execution path of modern systems. AI agents trigger actions across SaaS tools, internal services, and customer-facing workflows. Under real usage, issues around authentication, permissions, API limits, and long-running processes surface quickly.
This reality has pushed teams to look more closely at how integration tools behave beyond initial setup. Attention has shifted toward failure handling, state management, and visibility once workflows are live. These factors often determine whether a platform supports production workloads or becomes a source of operational friction.

In 2026, expectations are clear. Teams evaluating alternatives in the Workato category prioritize predictable behavior, operational control, and safe execution for agent-initiated actions over surface-level features or polished builders.
Here are the six Workato alternatives teams are actively using in 2026, along with where each one tends to fit best.
Comparison Table
| Capability (vs Workato) |
Composio |
Tray.ai |
Zapier |
Make.com |
n8n |
| Built for AI agents |
Native: designed for agent tool use and action execution |
No: oriented to human built workflows |
Partial: can be used by agents through Zaps, not agent native |
No: scenario automation, not agent focused |
Partial: can power agent tools, but you assemble the patterns |
| Developer friendly |
Native: API and SDK centric |
Partial: strong platform, heavier enterprise setup |
Partial: easy to start, limited deep customization |
Partial: flexible builder, some developer hooks |
Native: code friendly, extendable nodes, self hostable |
| Runtime action or tool selection |
Native: pick tools dynamically at runtime |
No: mostly pre defined workflow paths |
No: action set is fixed at design time |
No: module path is fixed at design time |
Partial: possible with branching, expressions, custom logic |
| Managed OAuth plus automatic token refresh |
Native: handles OAuth and refresh as part of connectors |
Native: OAuth supported, refresh handled in connectors |
Native: OAuth apps can auto refresh when configured |
Native: connections handle OAuth and refresh when configured |
Partial: usually supported, can vary by node and setup |
| Safe agent initiated actions |
Native: guardrails, scoped actions, safer execution patterns |
No: not built around agent safety controls |
No: limited agent specific approvals or guardrails |
No: limited agent specific approvals or guardrails |
Partial: possible with approvals and checks you build |
| Long running workflows |
Native: built to support longer executions and retries |
Native: supports long running enterprise workflows |
Partial: good for delays and scheduling, not long compute runs |
Partial: supports scheduling, but scenario run time is limited |
Native self hosted: configurable timeouts, Partial cloud
|
| API first execution |
Native: designed to be called and controlled via API |
Partial: APIs exist, platform first |
No: primarily UI driven automation |
Partial: some API and webhook driven patterns |
Partial: strong webhooks and APIs, depends how you deploy |
| Production reliability for agents |
Native: built for agent execution in production settings |
Partial: strong reliability, not agent specific |
No: best for business automation, not agent runtimes |
No: best for business automation, not agent runtimes |
Partial: can be reliable, depends on hosting and ops |
| Self hosting |
Self-hosting an =d private VPC |
No: SaaS only |
No: SaaS only |
No: SaaS only |
Native: first class self hosting option |
Workato Alternatives Explained
1. Composio
Composio is a developer-first platform that connects AI agents with 500+ apps, APIs, and workflows. It is built for teams deploying agents into real production environments, where integrations need to behave predictably and survive ongoing API changes rather than just work in controlled demos.

The platform is structured around agent-initiated actions instead of static automation flows. Common integration pain points, such as authentication, permission scoping, retries, and rate limits, are managed centrally, reducing the operational overhead that typically slows teams down as systems scale.
Composio emphasizes consistency and control at the execution layer. Tools are exposed with clear schemas and stable behavior, helping agents remain reliable across long-running workflows and high-volume use cases without constant manual intervention.
Features
- 500+ agent-ready integrations across SaaS and internal systems
- Centralized handling of OAuth, token refresh, retries, and API limits
- Native Model Context Protocol support with managed servers
- Python and TypeScript SDKs with CLI tooling
- Works with major agent frameworks and LLM providers
- Execution visibility and control for agent-triggered actions
Why is Composio a strong Workato alternative
Composio is designed for agent-driven execution where actions are selected at runtime rather than defined as static workflows. This model fits modern AI systems that need to interact with many external tools while maintaining consistent behavior around permissions, retries, and API limits.
By centralizing integration logic and exposing tools through stable, structured interfaces, Composio reduces operational overhead as systems scale. Teams can focus on agent behavior and decision-making while the platform handles execution details reliably across production environments.
Best for
Teams building AI agents that must operate across multiple services in production, especially when reliability and developer control matter more than visual workflow builders.
Benefits
- Faster production readiness for agent-based systems
- Reduced integration maintenance and breakage
- More predictable behavior under real-world load
- Cleaner separation between agent logic and tooling
- Better handling of auth and API edge cases
2. Tray (Tray.ai)
Tray.ai is built for teams that need to orchestrate complex, API-heavy workflows across large SaaS environments. It is commonly used when automations span many systems and require detailed control over branching, transformations, and execution flow.

The platform is optimized for structured automation rather than agent-native execution. Workflows are typically defined upfront and refined over time, which works well for predictable processes but can introduce friction for highly dynamic, agent-driven use cases.
Features
- Visual workflow builder with advanced branching and conditional logic
- Deep API connectors with support for custom requests
- Data mapping and transformation across steps
- Built-in retries, error handling, and execution controls
- Enterprise governance, access control, and security features
Why Tray is a viable alternative
Tray offers significantly more flexibility than basic iPaaS tools as workflows become more complex. Its strength lies in handling detailed API interactions and multi-step orchestration without requiring teams to build and maintain custom infrastructure.
Pros
- Strong support for complex and long-running workflows
- Fine-grained control over logic and execution
- Well-suited for enterprise-scale automation
- Reduces reliance on custom orchestration code
Cons
- Less suited for highly dynamic or agent-driven execution
- Setup and maintenance can be heavier than simpler tools
- Visual workflows can become hard to manage at a large scale
3. Zapier
Zapier is widely used for connecting everyday SaaS tools through simple, event-driven automations. It is optimized for speed and accessibility, allowing teams to set up workflows quickly without needing deep technical knowledge or custom infrastructure.

The platform works best when workflows are short, predictable, and built around common triggers and actions. While it has added more advanced features over time, its core strength remains ease of use rather than handling complex or highly dynamic execution patterns.
Features
- Thousands of prebuilt app integrations
- Trigger-and-action-based workflow builder
- Basic branching and filtering logic
- Built-in scheduling and webhook support
- Fast setup with minimal configuration
Why Zapier is a viable alternative
Zapier lowers the barrier to automation and remains a practical choice for teams that need to move quickly. For straightforward integrations and internal workflows, it often delivers results faster than heavier iPaaS platforms.
Pros
- Extremely easy to use and quick to deploy
- Broad integration coverage across SaaS tools
- Minimal operational overhead
- Accessible to non-technical teams
Cons
- Limited support for complex or long-running workflows
- Not well suited for agent-driven or API-heavy execution
- Can become expensive at scale
- Limited control over execution details
4. n8n
n8n is an open-source, developer-friendly automation platform that gives teams full control over how workflows are built, executed, and hosted. Unlike fully managed iPaaS tools, n8n can be self-hosted, making it attractive for teams that want ownership over infrastructure, data, and execution behavior.

n8n workflows are built using a node-based visual editor, but the platform is fundamentally code-capable. Teams can inject custom JavaScript logic, call arbitrary APIs, and design workflows that closely mirror real system behavior. This makes n8n flexible enough for non-standard integrations while still offering a visual layer for orchestration.
While n8n is increasingly used alongside AI systems, it is not agent-native by default. Agent-driven execution, retries, permission control, and long-running reliability must be explicitly designed and maintained by the team.
Features
- Open-source core with optional managed hosting
- Visual node-based workflow builder
- Custom code steps with full JavaScript support
- Native HTTP, webhook, and API integration nodes
- Self-hosting support for security and compliance needs
- Extensible via custom nodes and plugins
Why n8n is a viable alternative
n8n appeals to teams that want flexibility without vendor lock-in. By owning the execution environment, teams can tailor workflows to exact requirements, integrate deeply with internal systems, and adapt quickly as APIs or business logic change.
For organizations with engineering resources, n8n provides a powerful foundation for building bespoke automation layers that align closely with internal architecture.
Pros
- Full control over execution and infrastructure
- Open-source and highly extensible
- Strong fit for custom and internal integrations
- Suitable for self-hosted and regulated environments
Cons
- Operational responsibility sits with the team
- Requires engineering effort to maintain reliability
- Not designed for agent-native, runtime action selection
- Auth handling, retries, and governance must be built manually
5. Make.com
Make.com focuses on visual workflow orchestration for teams that need more flexibility than basic trigger-action tools, without moving fully into code-first systems. Workflows, called scenarios, are built using a drag-and-drop interface that supports branching, looping, data transformation, and conditional logic.

Make.com sits between lightweight automation tools and enterprise iPaaS platforms. It is often evaluated when teams want to model moderately complex processes across SaaS tools, internal systems, and APIs, while keeping workflows understandable to non-engineers.
The platform assumes workflows are largely defined upfront. While it supports HTTP modules and custom API calls, execution remains scenario-driven rather than agent-selected at runtime.
Features
- Visual, drag-and-drop scenario builder with branching and loops
- Broad SaaS integration library with custom HTTP/API modules
- Data mapping, filtering, and transformation tools
- Scheduling, webhooks, and event-based triggers
- Execution history and basic error handling controls
Why Make.com is a viable alternative
Make.com offers significantly more control than simple automation tools while remaining accessible to operations and business teams. It allows complex logic to be expressed visually, which makes it easier to reason about workflows that span multiple systems without introducing full custom infrastructure.
For teams that want flexibility but still value visual clarity and faster iteration, Make.com can serve as a practical middle layer between no-code tools and developer-heavy platforms.
Pros
- Strong visual modeling for complex workflows
- More flexible logic than basic trigger-action tools
- Good balance between power and usability
- Suitable for cross-functional teams
Cons
- Workflows must be largely predefined
- Not designed for dynamic, agent-initiated execution
- Limited control over deep API governance and permission boundaries
- Debugging becomes harder as scenarios grow large and interconnected
Comparison Table
| Capability (vs Workato) |
Composio |
Tray.ai |
Zapier |
Make.com |
n8n |
| Built for AI agents |
Yes |
❌ |
⚠️ |
❌ |
⚠️ |
| Developer friendly |
Yes |
No |
No |
No |
Yes |
| Runtime action/tool selection |
✅ |
❌ |
❌ |
❌ |
❌ |
| Managed OAuth & token refresh automatically |
✅ |
✅ |
⚠️ |
⚠️ |
⚠️ |
| Safe agent-initiated actions |
✅ |
❌ |
❌ |
❌ |
⚠️ |
| Long-running workflows |
✅ |
✅ |
❌ |
⚠️ |
⚠️ |
| API-first execution |
✅ |
⚠️ |
❌ |
⚠️ |
⚠️ |
| Production reliability for agents |
✅ |
⚠️ |
❌ |
❌ |
⚠️ |
- ✅ Native and well-supported
- ⚠️ Possible but not core
- ❌ Not a primary focus
Which One Should You Choose?
The right platform depends on what your system needs to optimize for. A practical way to think about the decision in 2026 is to map it to how your workflows actually behave.
-
Speed to production: Choose an agent-first platform with deep tool coverage, native agent protocol support, and solid SDKs.
-
Governance and compliance: Prioritize platforms that offer audit logs, policy controls, role-based access, and strong security guarantees.
-
Permission control: Look for fine-grained scopes, runtime authorization, and safe handling of agent-initiated actions.
-
Embedded integrations: Pick a platform designed for in-app, customer-facing integration flows with customizable UX.
-
Rapid experimentation: Visual builders and fast setup help validate workflows quickly.
-
Long-term control: Developer-centric or API-first platforms tend to scale better as systems become more complex.
A common pattern is to start with tools optimized for speed and iteration, then move to an agent-focused integration layer once workflows become production-critical.
Closing
Choosing an integration platform in 2026 comes down to how well it supports real execution, not how polished it looks in setup. As AI agents take on more responsibility inside products and internal systems, integrations need to behave predictably under load, handle edge cases cleanly, and surface failures clearly.
Each platform covered here optimizes for a different set of constraints. Composio focuses on agent-driven execution; Tray and Zapier support structured automation at different levels of complexity. Make.com excels at visually modeling complex, predefined workflows, and n8n appeals to teams that want open-source flexibility and infrastructure ownership. The right choice depends less on feature breadth and more on how closely a platform matches the way your systems actually operate in production.
Teams that evaluate these tools through the lens of reliability, control, and long-term maintenance tend to make better decisions than those optimizing for speed alone. In 2026, integration layers are no longer optional infrastructure. They are part of how systems execute.