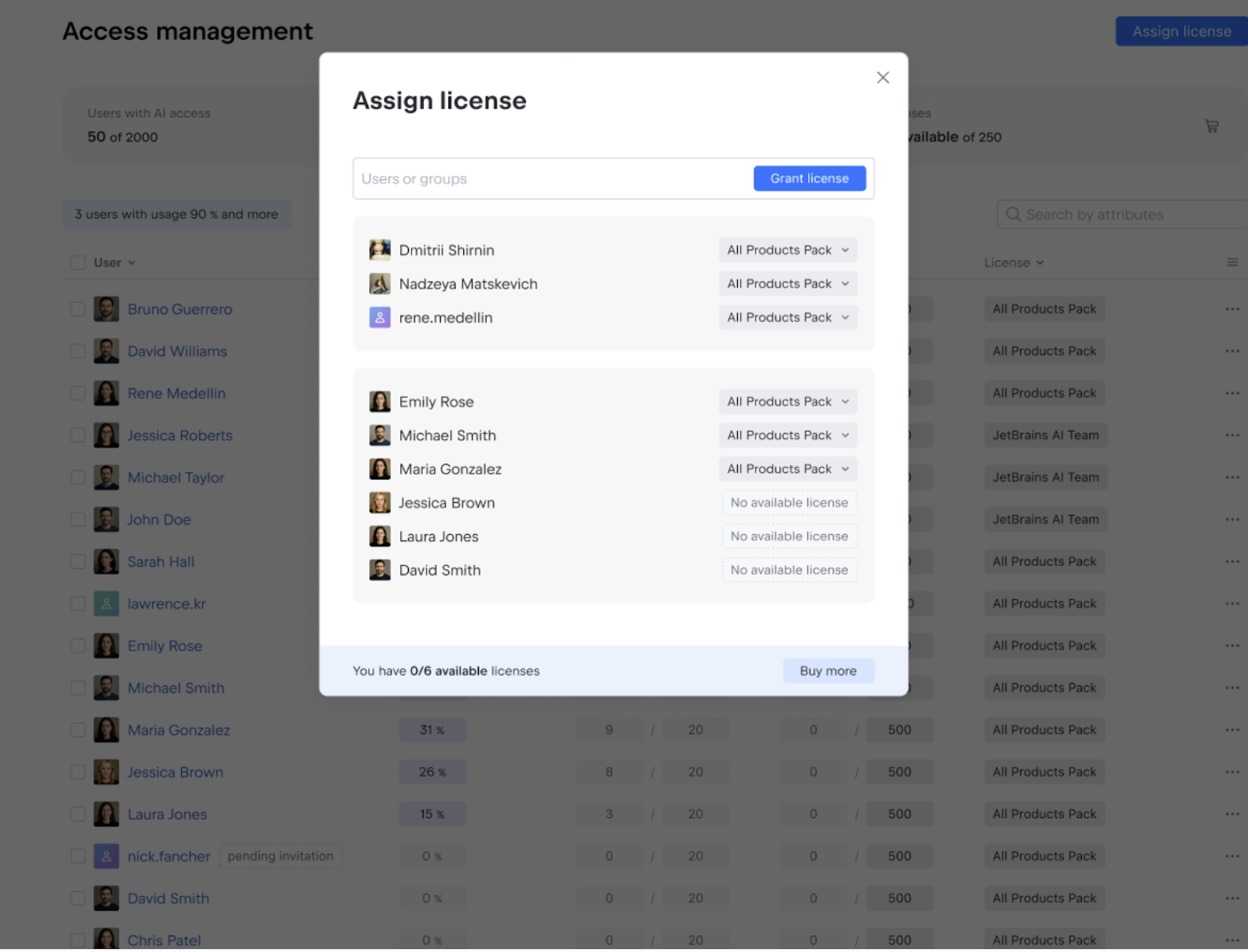
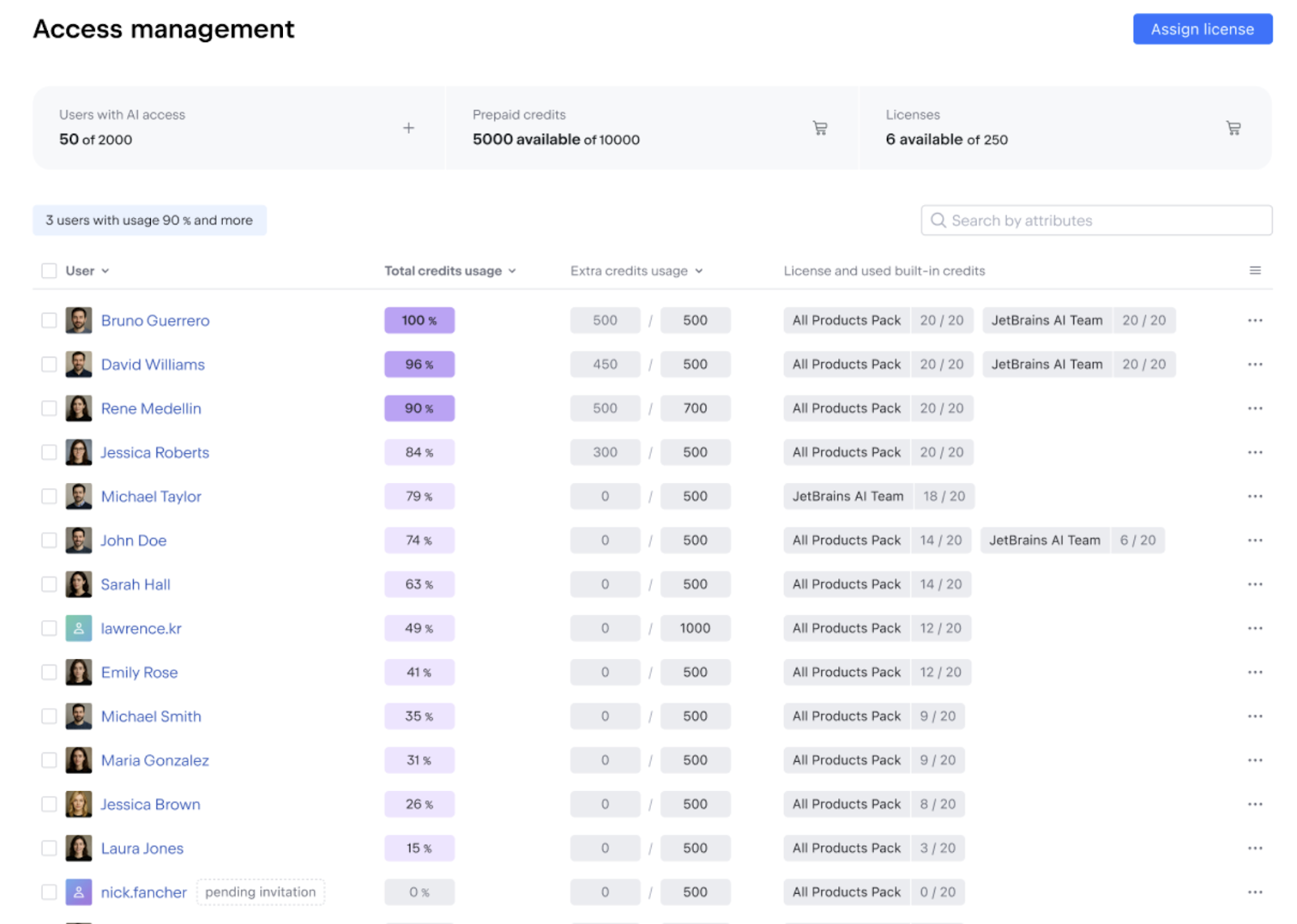
Recently, news from Postman has caused quite a stir in the developer community. According to their official blog and emails sent to users, Postman’s pricing and product plans are undergoing a major overhaul effective March 1, 2026.

The most critical change is to the Free plan, which currently supports team collaboration. It will be adjusted to single-user only. This means that if your team relies on the free version of Postman for collaborative API development and testing, you will soon be forced to upgrade to a paid Team plan.
For many small teams with limited budgets, open-source contributors, and learners, this is an issue that cannot be ignored. When a familiar tool no longer offers free collaboration, finding a suitable alternative becomes urgent.
What Do the Changes to Postman Mean?
Before discussing alternatives, it’s necessary to clearly understand the specific impact of Postman’s adjustments. This change isn’t just a simple feature reduction; it’s a strategic shift in product positioning that directly affects how free users operate.
Core Restrictions of the Free Plan
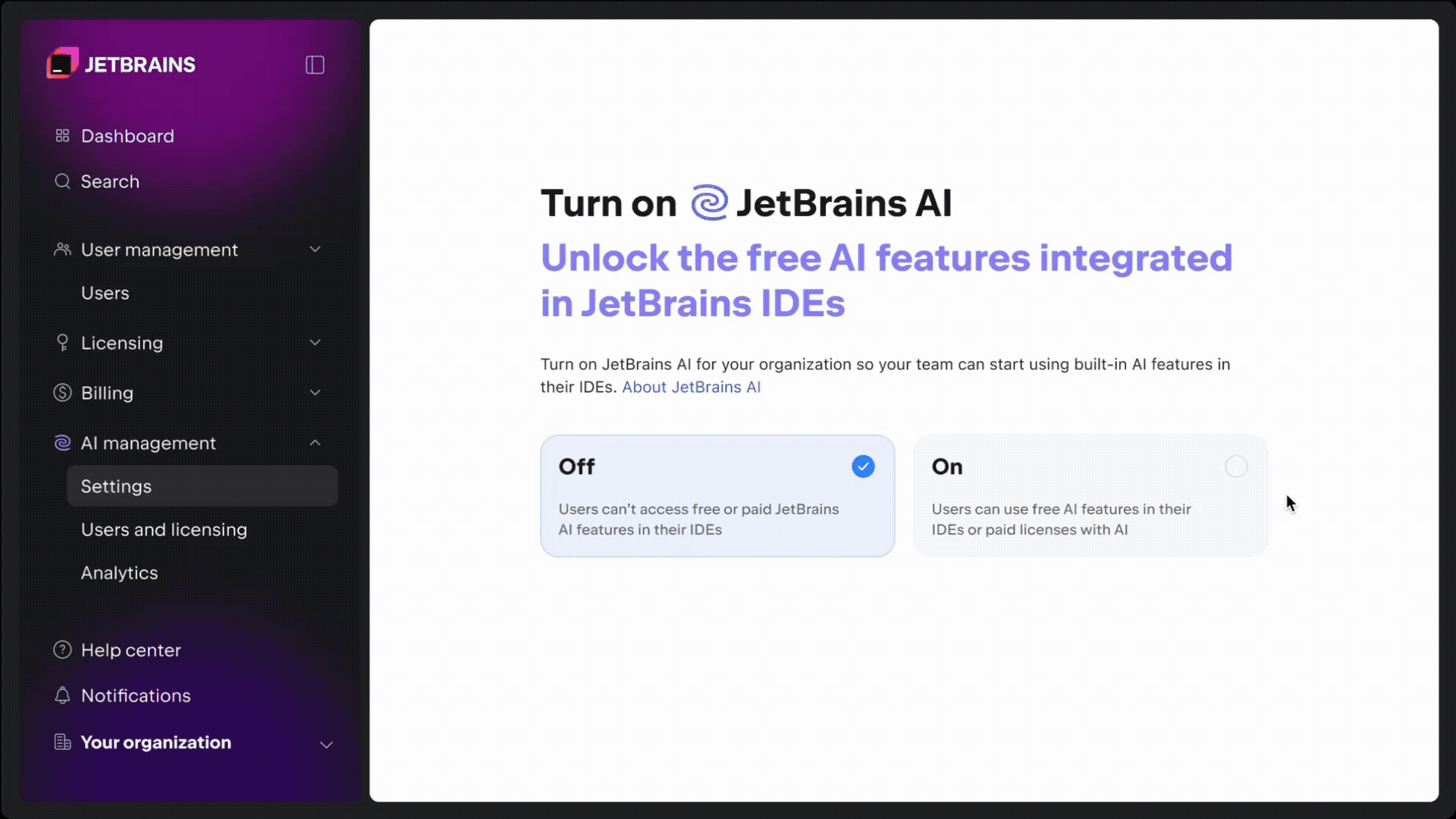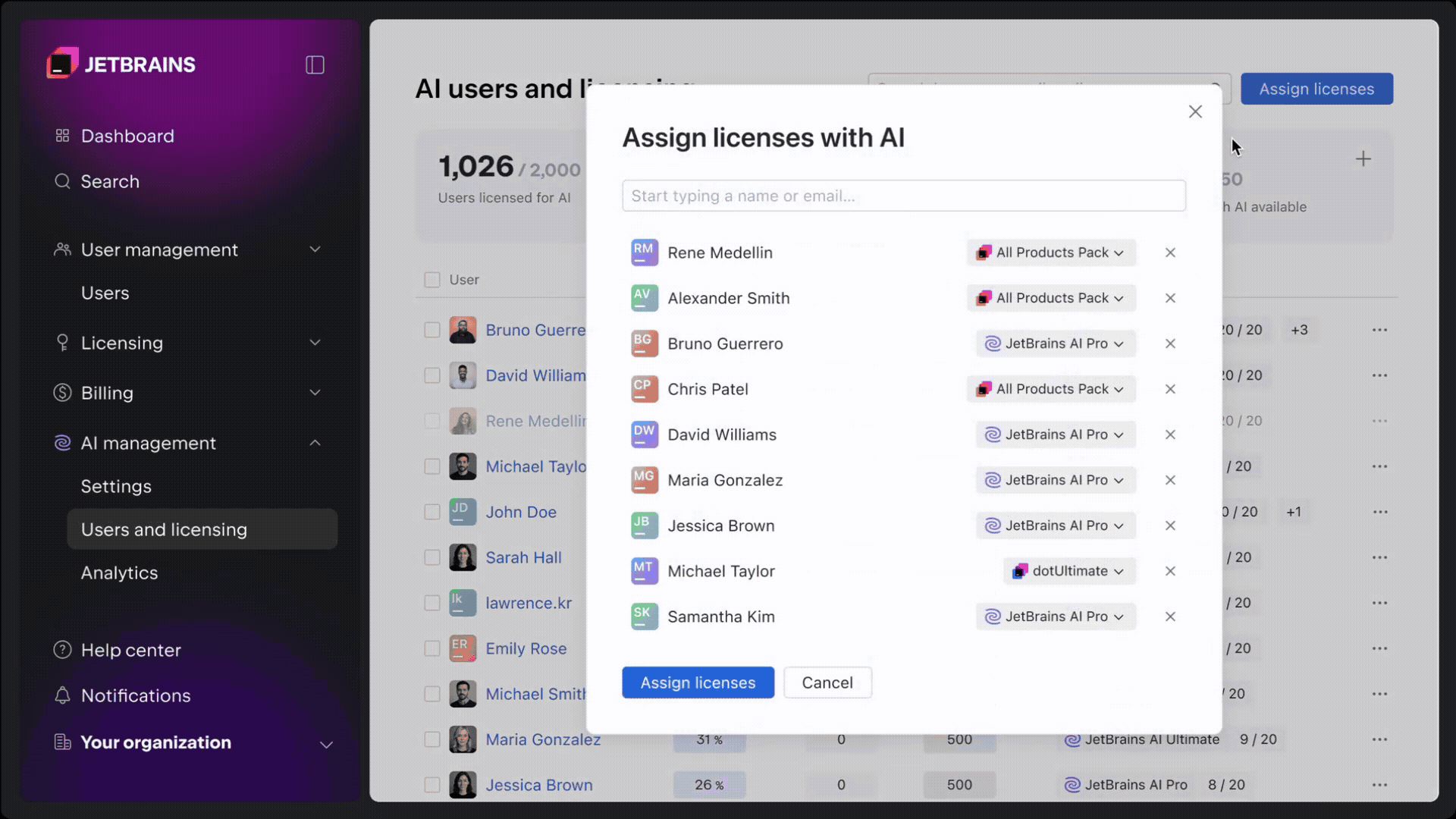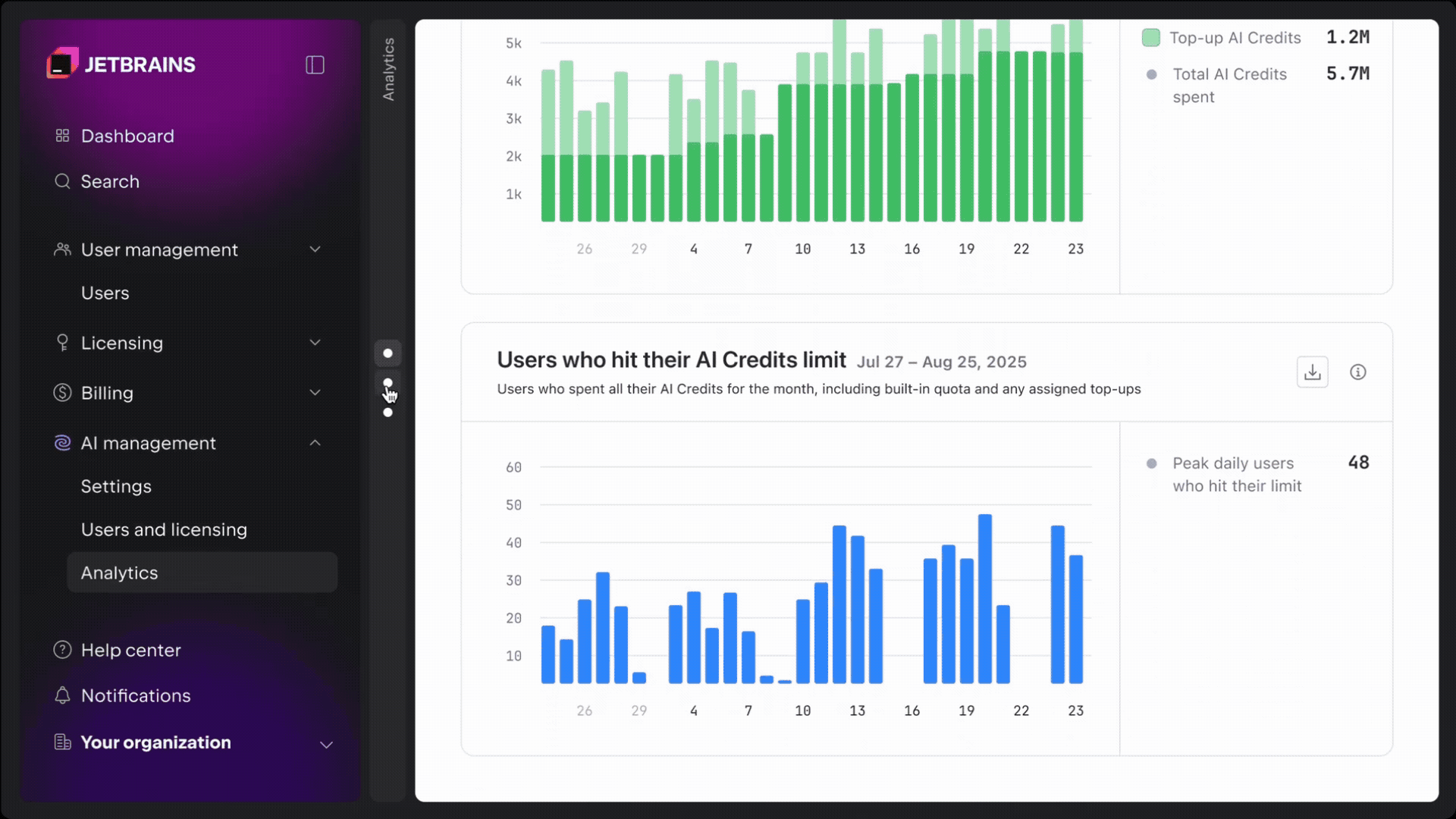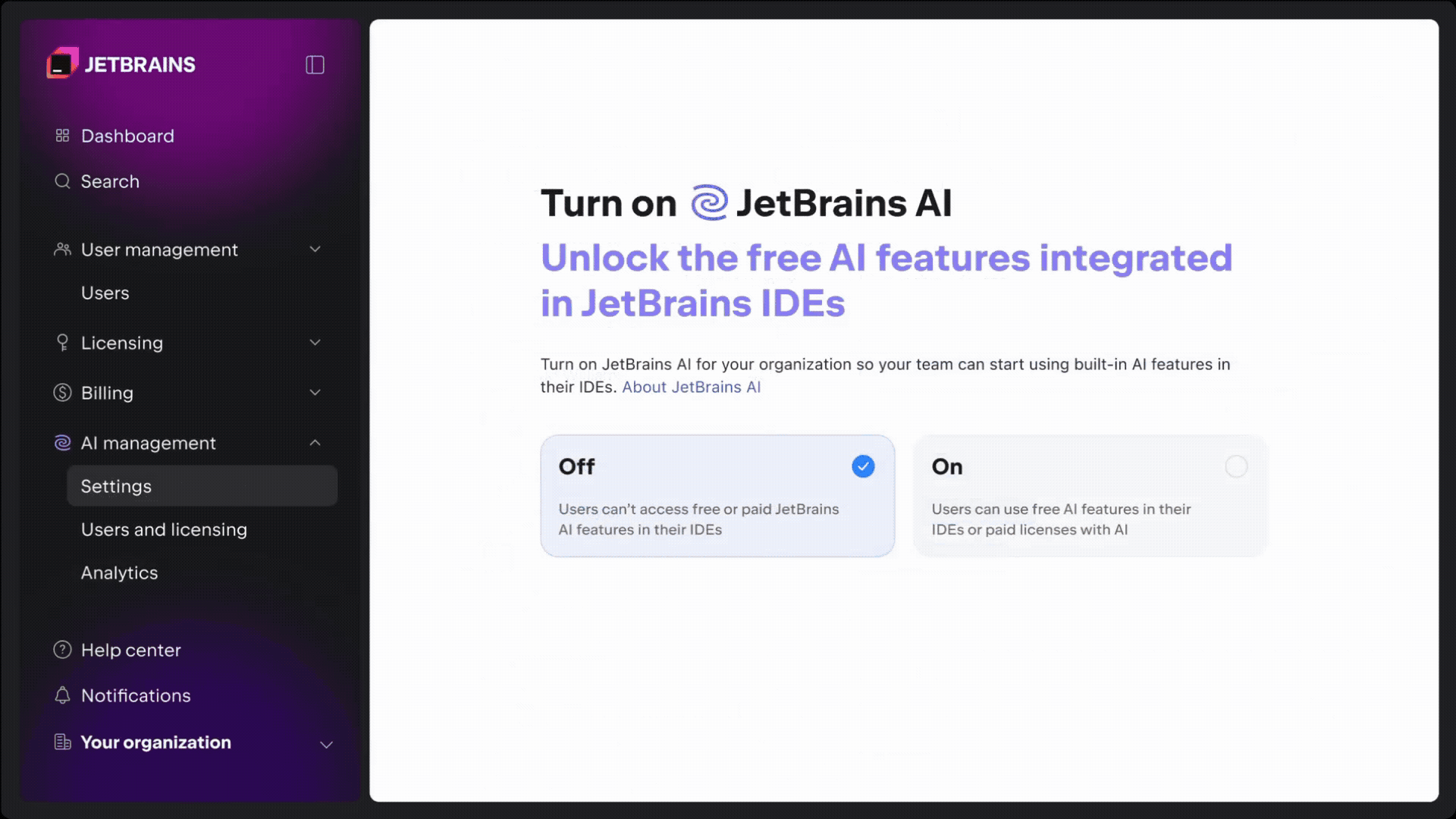
According to Postman, starting March 1, 2026, the new Free plan will be strictly limited to a single user.
This means the workflow of inviting multiple members to a Workspace, sharing API Collections, and synchronizing development progress—features we’ve taken for granted—will no longer exist in the free version. Any scenario requiring collaboration between two or more people will require migration to a paid plan.
For users accustomed to collaborating within Postman, this presents a direct challenge. Either the entire team pays for collaboration features, or you regress to a primitive state where everyone manages APIs locally on their own machines—a move that undoubtedly kills development efficiency and consistency.
Why You Need an Alternative
Postman’s new plans introduce many powerful features, such as native AI capabilities, deeper integration with Git workflows, and a brand-new API Catalog. These are indeed attractive for large enterprises or teams pursuing extreme efficiency.
However, for many developers and smaller teams, the most basic and core requirement is simply stable and free team collaboration. When this fundamental need becomes a paid feature, cost becomes an unavoidable factor.
Therefore, finding a tool that satisfies core functions like API design, debugging, and testing, while also providing complete team collaboration capabilities on a free tier, is the most practical choice.
Enter Apidog, an all-in-one API collaboration platform that combines API design, development, and testing. With its robust free team collaboration capabilities, it has become a top contender for developers looking to migrate.
Try it

Why Choose Apidog?
Among the myriad of API tools available, Apidog has a very clear positioning: an all-in-one API platform built for team collaboration. It is not just an API request tool; it spans the entire API lifecycle from design and documentation to development, testing, and release.
Most importantly, Apidog’s core team collaboration features are generous for free users, making it the ideal choice to counter Postman’s policy changes.
Here is a simple comparison to visualize Apidog’s advantages in team collaboration:
|
Feature |
Postman (Free Plan after March 2026) |
Apidog (Free Plan) |
|
Team Size |
Limited to 1 User |
Up to 4 Users |
|
Collaboration |
Not supported (Upgrade required) |
Real-time data sync, interface comments, permission management |
|
API Design & Docs |
Manual writing supported |
Visual design support with auto-generated, shareable documentation |
|
Mock Server |
Supported, with limits |
Powerful advanced Mock features with custom rules |
|
Auto Testing |
Supported, with limits |
Support for test case orchestration, assertions, and test reports |
|
Core Positioning |
Individual Developer Tool |
Team Collaborative API Platform |
As shown in the table, while Postman’s free version retreats to being a personal tool, Apidog continues to champion team collaboration as a core value. It doesn’t just solve the problem of “can we collaborate?”; it offers richer functionality in the depth and breadth of that collaboration.
Migrating from Postman to Apidog
Moving from a familiar tool to a new one often brings anxiety about data loss and learning curves. Fortunately, Apidog provides a seamless Postman data import feature, making the entire migration process smooth and painless.
The process consists of two main steps: exporting data from Postman and importing it into Apidog.
1. Exporting Postman Data
In Postman, your core assets are usually Collections and Environments.
A Collection is a set of all your saved API requests, including URLs, methods, headers, bodies, etc. An Environment stores variables for different contexts, such as API_HOST for development versus production.
First, you need to export this data to files.
- Open the Postman client and find the
Collectionyou want to export in the left navigation bar.

-
Click the three dots (
...) icon next to the Collection and select Export. -
In the popup window, choose the recommended Collection v2.1 format and save the JSON file to your local machine.

Next, export your environments in the same way. Click the Environments tab on the left, find the environment you need, click the three dots (...), select Export, and save it as a JSON file.

2. Importing Data into Apidog
Once you have your JSON files, you can import them into Apidog.
-
Open Apidog and enter your project.
-
Click “Settings” (usually a gear icon) in the left sidebar.
-
Select “Import Data” and choose the “Postman” option.

Apidog will present an upload interface. You can drag and drop your exported Collection and Environment JSON files directly into the upload area. Apidog supports uploading multiple files at once and will automatically recognize and process them.
After uploading, Apidog parses the file content, seamlessly converting Postman requests, directory structures, and environment variables into Apidog’s interfaces and environments. Once the import is successful, you’ll see all your familiar API requests ready to go in the Apidog interface.

Start Collaborating in Apidog
With data migration complete, you can now truly experience the collaborative benefits of Apidog.
Invite Team Members
The first step in collaboration is building your team. In Apidog, inviting colleagues is straightforward.
-
Click on “Settings” or “Members/Permissions” in your project or team dashboard.
-
Invite new members via a shareable link or email invitation.

Unlike Postman’s upcoming single-user limit, Apidog allows you to add up to 4 team members for free. It also offers a flexible permission management system, allowing you to assign different roles (Admin, Editor, Read-only, etc.) to ensure project data security.
Experience the All-in-One Workflow
Apidog’s strength lies in its “All-in-One” design philosophy. It’s not just a Postman replacement; it’s a platform that covers the full API lifecycle.
-
Design First: Collaboration often starts with API design. You can define paths, parameters, request bodies, and response structures visually directly on the platform.
-
Auto-Generated Docs: Once the API is designed, professional and beautiful API documentation is generated automatically. You can share this online with frontend colleagues or third-party partners, who can view and debug directly in their browser without installing software.
-
Smart Mocks: For frontend developers, Apidog’s Mock function is a game-changer. Based on your API design, Apidog automatically generates realistic Mock data. This means frontend work doesn’t need to wait for the backend interface to be finished—you can develop and integrate based on Mock data immediately, significantly boosting parallel development efficiency.
-
Automated Testing: When the backend interface is ready, team members can perform debugging and automated testing within Apidog. You can combine multiple requests into a test case, set assertions to verify results, and run all tests with one click to generate detailed reports.
Conclusion
Facing Postman’s free tier adjustments, there’s no need to panic. The tech ecosystem is constantly evolving. While Postman’s choice is part of their business strategy, for the vast majority of developers and teams, this is an opportunity to discover and embrace tools like Apidog—tools designed for modern team collaboration that are more integrated, efficient, and generous with their free tiers.