Have you imagined that in a search system, you are searching for “Best places for a day-long tour?” and immediately you get results like:
-
Good spot for one day tour with family and friends
-
Places to visit within a short time
-
Best short picnic tour with natural view
How do you get these results that don’t exactly match your search queries?
Also, have you imagined how your company’s dedicated AI chatbot answers users’ queries related to your company’s information, where the AI chatbot models are actually not trained with your company’s information!
What is actually behind these things? Where do search engines get their information?
The simple answer is Vector Database. Vector Database is the thing that answers your imagination.
In this article, we will discuss what is Vector Database and how Vector Database resolves these problems? Later, we will know how AWS Vector Databases empower semantic search and AI applications.
So, before explaining Vector Database, let’s first understand the problems it resolves, such as semantic search and one of the core components of modern AI applications: RAG (Retrieval-Augmented Generation).
What do you mean by semantic search?
In the very first section of this article, you searched for suggestions like best places for a day-long tour, and you got similar results that match your intention, understand your query’s meaning.
Semantic Search is a search technique that focuses on the meaning and intent behind your query, rather than just matching the exact queries. Unlike the traditional keyword-based search (which looks for exact word matches), Semantic Search uses machine learning to understand the context, intents, and relationships between words. It tries to answer the question: “What is the user actually looking for?”
So now, what does semantic search use to work?
Semantic search uses several things to work, like a data chunker, embedding models (large language models), vector databases, and several indexing algorithms.
Here is an image for the semantic search process that can give you some idea.

RAG (Retrieval-Augmented Generation):
Now, suppose I want to build a chatbot for my company, “Dynamic Solution Innovators Ltd. (DSi)” that can answer users about the company-specific information. And for this, what will I need? I need an LLM model which can understand user queries and will also have my company’s (DSi) information, right? As you know, only an LLM model that can understand natural language will not be enough, as it needs your company’s information so that it can answer.
Now, for this, you can train an LLM model by fine-tuning it with all of your company data. However, this approach is time-consuming, costly, and complex. In addition, over time, a lot of information about your company will change, and regularly re-training the LLM model with new data will become even more difficult. Moreover, training the model only on company data does not guarantee that you will get correct answers to all questions, because an LLM generates responses based on predictions from the data. In such cases, there is a chance of hallucination or incorrect answers.
In this case, you can take another approach. You can provide all of your company’s information as context to a foundation model with every question. Since a foundation model is capable of understanding and processing language, there is no need to train it separately. By supplying the necessary context, it can generate answers based on that context. This way, even if your company or product data changes, it is not a problem, because the data is being provided dynamically as context. However, there is still a problem with this approach. If your company’s data is very large, like a hundred gigabytes, then what happens? The model cannot realistically process such a huge amount of data as context every time it answers a question. And here, RAG (Retrieval-Augmented Generation) comes to rescue you, it provides an excellent solution to all of these problems.
The full process of RAG generally involves these 4 steps.
-
Ingestion/Indexing: Company or product data is split into small chunks, converted into vector embeddings using an embedding model, and stored in a vector database for efficient retrieval.
-
Retrieval: When a user submits a query, it is converted into a vector embedding and matched against the vector database to retrieve only the most relevant information.
-
Augmentation: The user’s query and the retrieved relevant information are combined to generate a prompt that includes both the question and the necessary context.
-
Generation: The LLM generates a response based on the augmented prompt, producing more accurate and context-aware answers.
So you can see the power of Vector databases here. It is one of the backbones of the RAG.
You will have a better understanding of RAG from this image.

To learn more about RAG you can read this nice pinecone’s article.
Now let’s come to the point!
What is Vector Database?
To know what Vector Database is, let’s start with a scenario. Suppose you want to store this image in a database. So, how would you store it, and how would you describe it as an image of a sunset in Mountain Vista?

If we want to use a relational database like PostgreSQL/MySQL to store this image, we will generally save its properties like:
So these are the properties that you can use later to retrieve this image or describe it. But can you realise that this kind of information largely misses the images’ overall semantic context? Because how would you query for images with similar colour palettes using this information? These concepts are not really represented in these structure fields, and that disconnects how computers store data and how humans understand it. This is a semantic gap.
Now to retrieve information from a traditional database, it will use like
SELECT *
WHERE
color = ‘orange’
It is kind of short because it does not capture the information of multidimensional unstructured data. And that’s where Vector Database comes in.
A vector database is a database to store, index, and rapidly search high-dimensional data points called vector embeddings. These vectors are high-dimensional data points that capture semantic meaning.
You can store any kind of data, like text, audio, or video, in a vector database, but before storing, you need to convert this data into vector embeddings, as a vector database only stores vector embeddings.

What Are Vector Embeddings?
Vector Embeddings are high-dimensional numerical arrays that represent the semantic meaning of text, images, or audio. When text, images, audio, or other content is processed by an embedding model, it is converted into a high-dimensional vector. These vectors are stored in the vector database.
The embedding models are machine learning models that convert these types of complex unstructured data into numerical arrays that contain semantic meaning.
Vector database primarily uses Approximate Nearest Neighbor (ANN) search algorithms for efficient similarity search across high-dimensional data. Later on in the next article we will discuss how vector databases actually work.
AWS Vector Database Services:
AWS does not provide any standalone vector database service. It offers multiple vector database capabilities embedded across its existing services including Amazon OpenSearch Service, RDS/Aurora for PostgreSQL, Amazon MemoryDB, Amazon DocumentDB, and specialized tools like Amazon Neptune Analytics, catering to different needs for AI/ML applications like Retrieval-Augmented Generation (RAG) and recommendation engines. Instead of a single universal solution, it allows teams to choose the option that best fits their requirements while keeping data near the workloads that rely on it.
Amazon RDS/Aurora for PostgreSQL with Vector Search (pgvector)
What Amazon RDS/Aurora for PostgreSQL does:
- Stores vector embeddings in PostgreSQL tables
- Performs fast similarity search and semantic similar items
- Combines vector search with full SQL operations like filters, joins, sorting
- Allows in-database embedding generation
What makes Amazon RDS/Aurora for PostgreSQL different:
- Everything stays in one PostgreSQL database. No separate vector DB
- Full ACID transactions with relational features preserved
- Direct integration with Bedrock that generate embeddings with simple SQL calls
- Hybrid search (vector + keyword) in single query
Amazon OpenSearch with vector engine / K-NN
What Amazon OpenSearch with vector engine does:
- Stores high-dimensional vector embeddings in dedicated indexes (knn_vector field)
- Supports semantic/meaning-based search
- Enables hybrid search that combines vector similarity with keyword/full-text, filters, and aggregations in one query
What makes Amazon OpenSearch with vector engine different:
- Purpose-built search & analytics engine that excels at large-scale, complex queries beyond just vectors
- True hybrid/combined search in single query like keyword + vector
Amazon MemoryDB for Redis
What Amazon MemoryDB for Redis does:
- Stores vector embeddings in Redis hashes or JSON documents
- Performs ultra-fast k-Nearest Neighbors (k-NN) similarity search
- Enables semantic/meaning-based search at in-memory speed
- Provides real-time indexing and updates
What makes Amazon MemoryDB for Redis different:
- Fastest vector search on AWS with nearly single-digit millisecond latency
- Multi-AZ durability with 99.99% availability. Data persists across failures, unlike pure cache
- Redis ecosystem compatibility, which can use existing Redis clients, commands, and tools
Amazon DocumentDB (with MongoDB compatibility)
What Amazon DocumentDB does:
- Stores vector embeddings directly within JSON documents alongside operational data
- Performs similarity search using HNSW (Hierarchical Navigable Small Worlds)
- Enables hybrid search by combining vector similarity with traditional document filtering
- Integrates with LangChain and other AI frameworks for building semantic search applications
What makes Amazon DocumentDB different:
- Eliminates the need to move data to a separate vector database; you can run vector queries on your existing JSON data.
- Native JSON support means you can store embeddings next to complex, nested attributes without rigid schema definitions.
- Allows you to use standard MongoDB drivers and tools to manage vector data.
Amazon Bedrock Knowledge Bases
What Amazon Bedrock Knowledge Bases does:
- Fully manages the end-to-end RAG workflow
- Automates the ingestion process: connects to data sources like S3, splits text into chunks, generates embeddings, and stores them in a vector index
- Retrieves relevant context at runtime to augment LLM prompts for more accurate responses
What makes Amazon Bedrock Knowledge Bases different:
- Abstracts away the complexity of building data pipelines. You don’t need to write code to chunk documents or call embedding APIs.
- It acts as a connector rather than just storage. It manages the synchronization between your raw data and your vector db store
- Connects natively with Bedrock Agents to give AI assistants access to proprietary data without manual implementation.
In summary, the table below outlines when to use each service and what makes it different

References
- https://docs.aws.amazon.com/prescriptive-guidance/latest/choosing-an-aws-vector-database-for-rag-use-cases/vector-db-options.html
- https://aws.amazon.com/what-is/vector-databases/
- https://www.pinecone.io/learn/vector-database/
- https://www.linkedin.com/pulse/aws-vector-databases-explained-semantic-search-rag-systems-jon-bonso-rgx0f/
- https://www.pinecone.io/learn/retrieval-augmented-generation/
- https://www.dsinnovators.com/services/cloud-platform-engineer.html
- https://www.youtube.com/watch?v=gl1r1XV0SLw&t=1s
- https://www.youtube.com/watch?v=T-D1OfcDW1M
- https://www.datacamp.com/tutorial/mastering-vector-databases-with-pinecone-tutorial










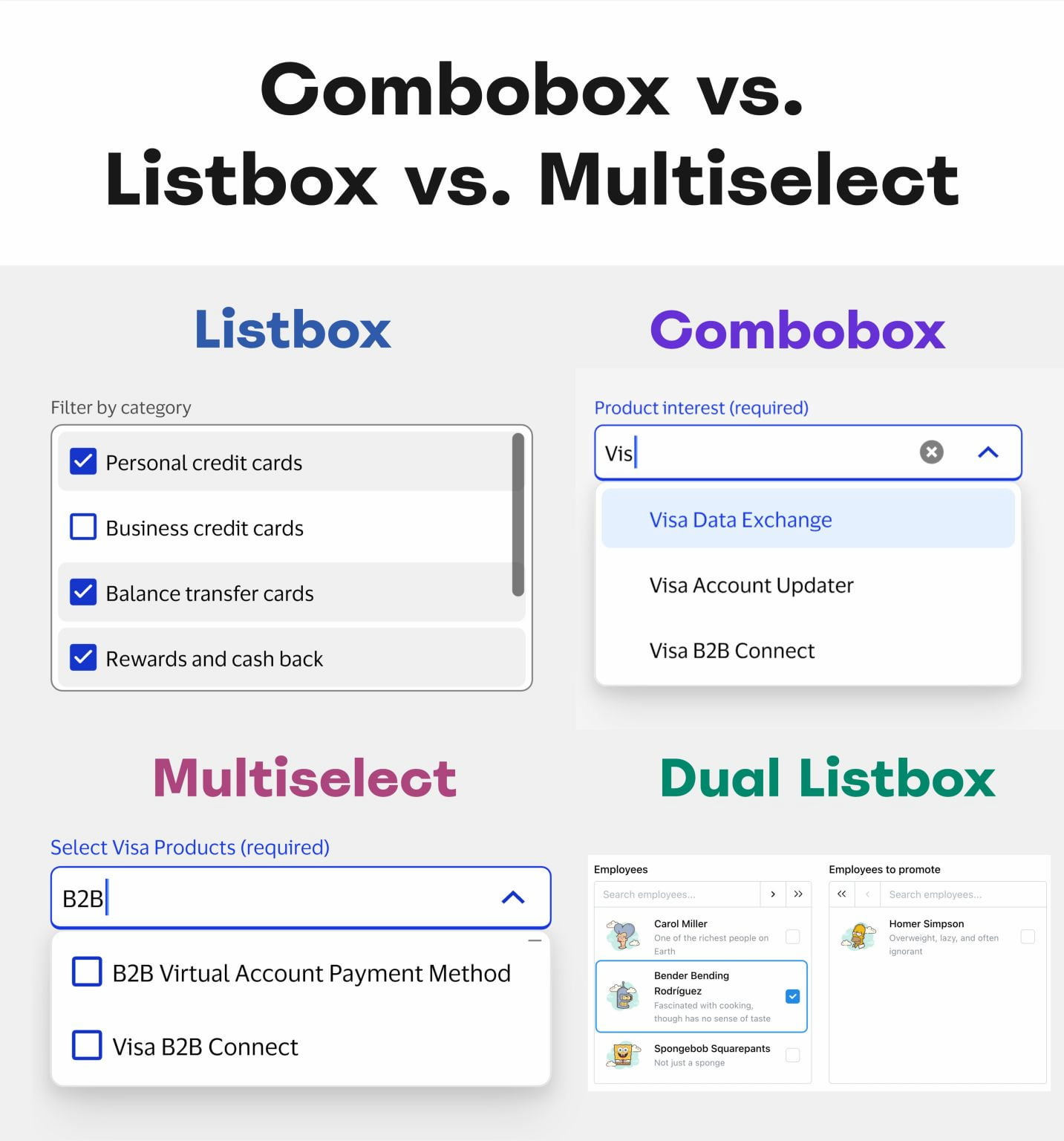
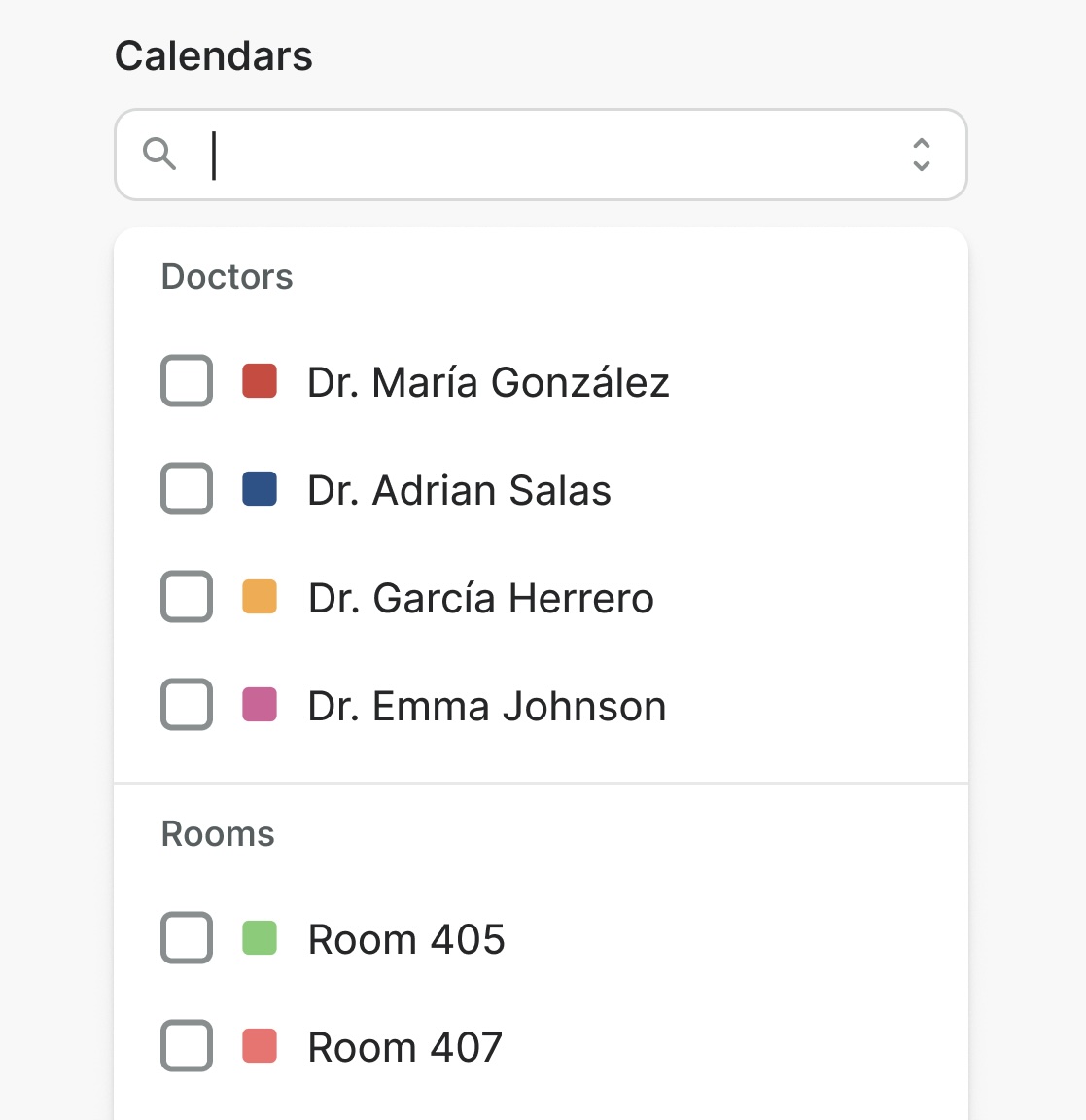
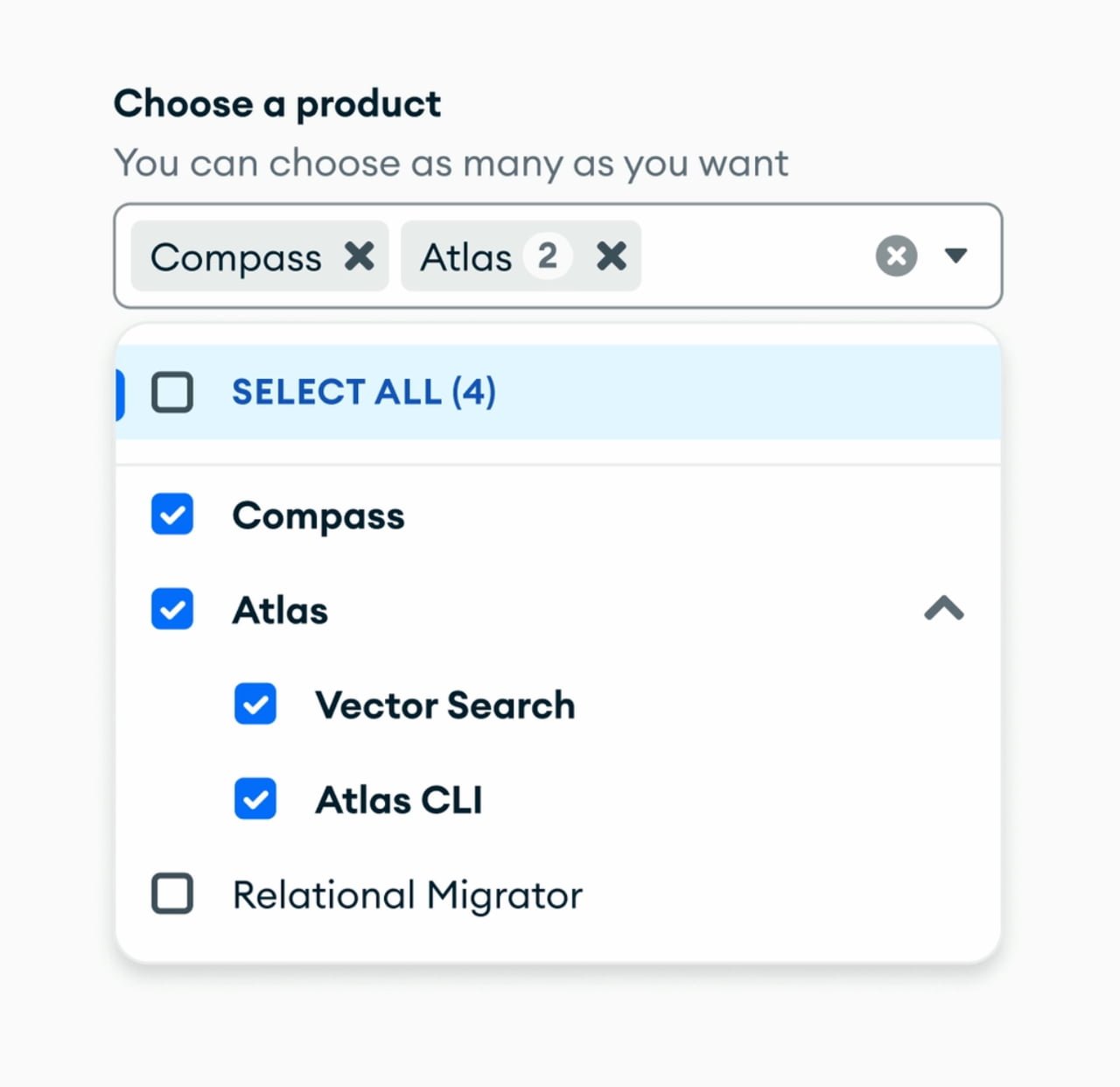

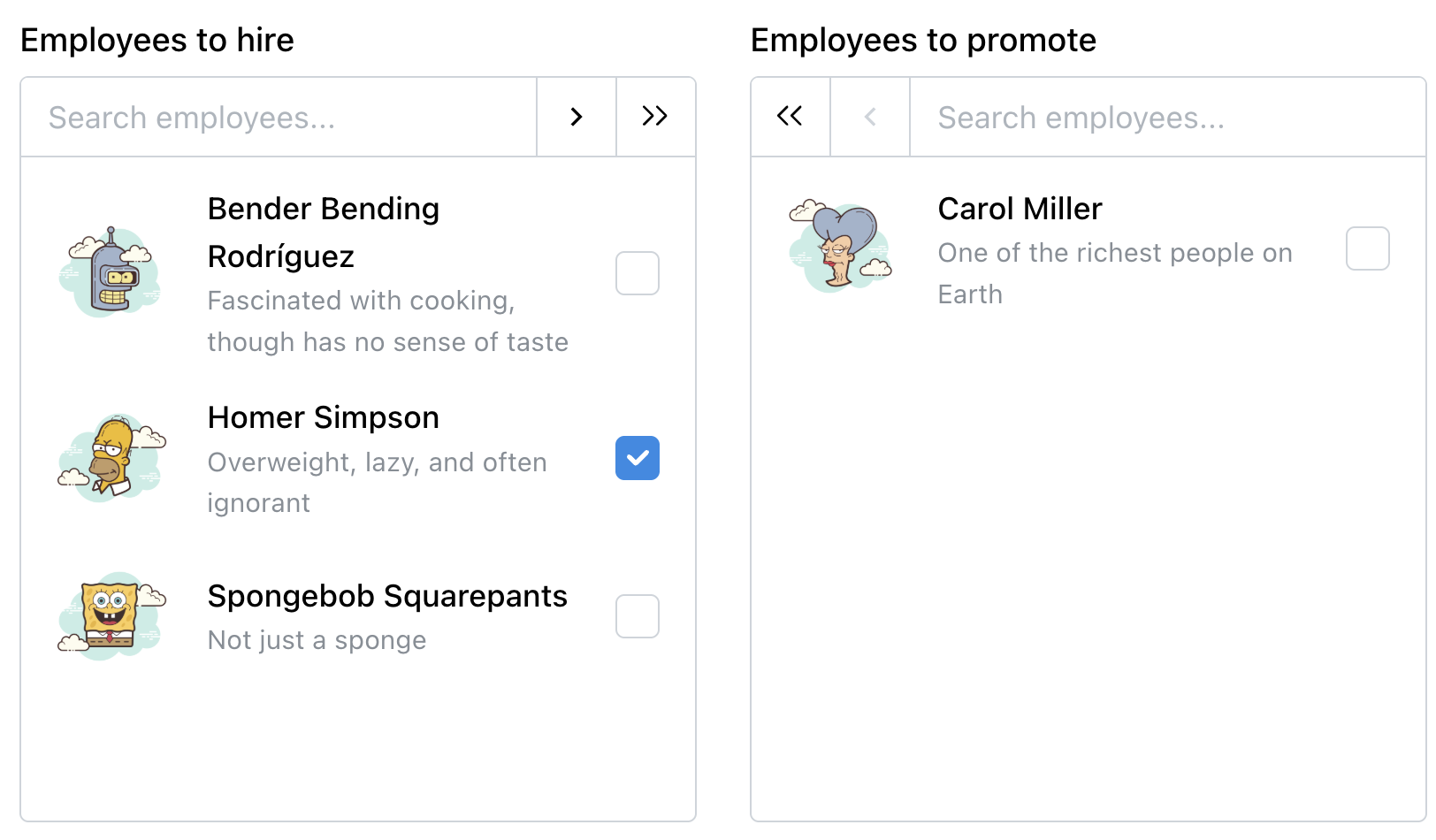
 Meet Design Patterns For AI Interfaces, Vitaly’s video course on interface design & UX.
Meet Design Patterns For AI Interfaces, Vitaly’s video course on interface design & UX.