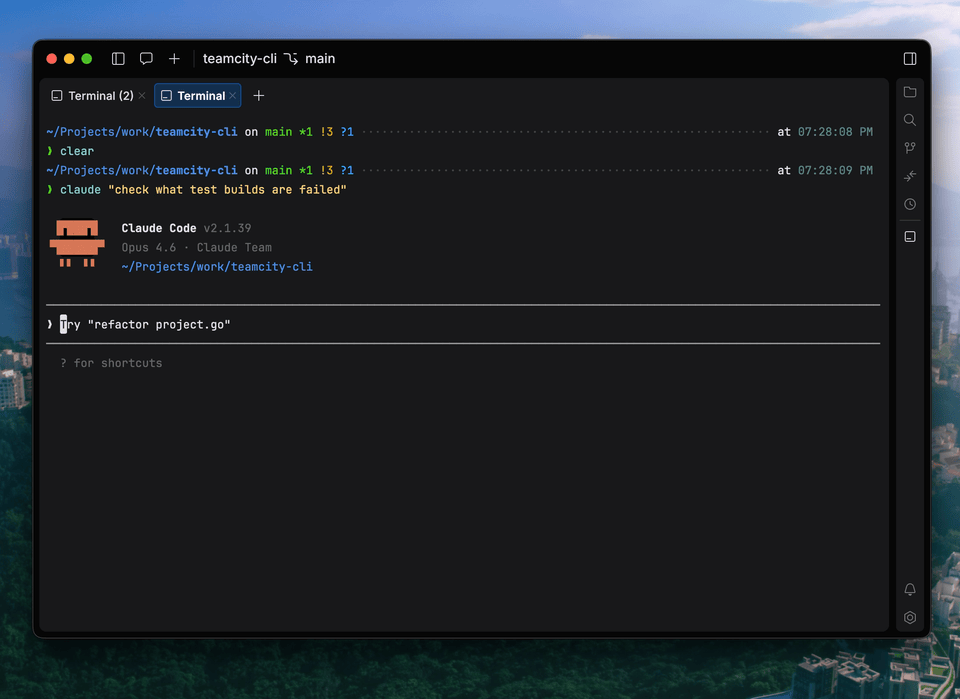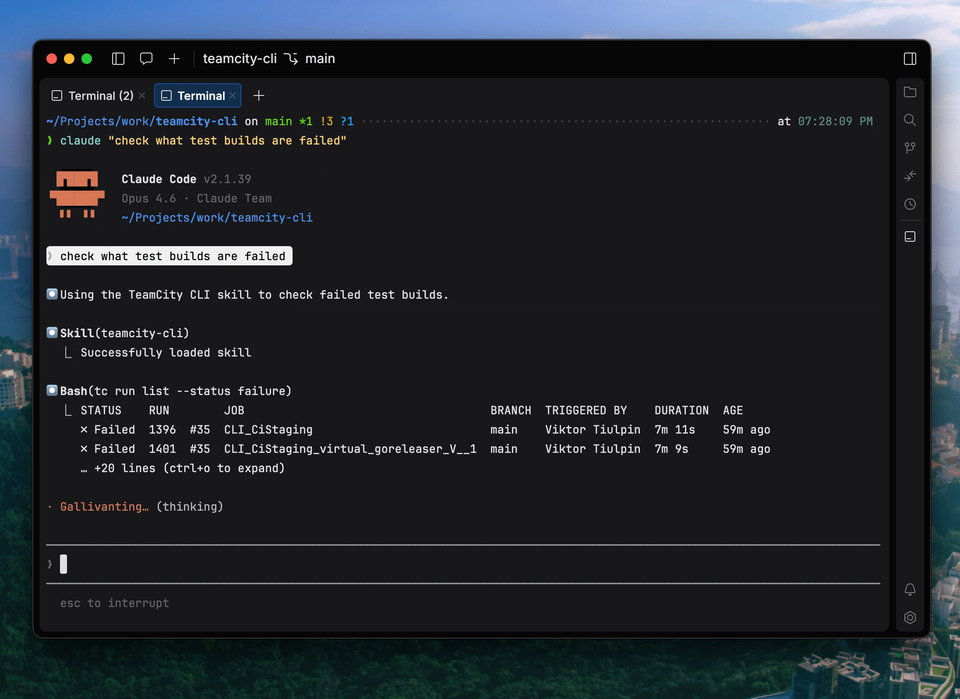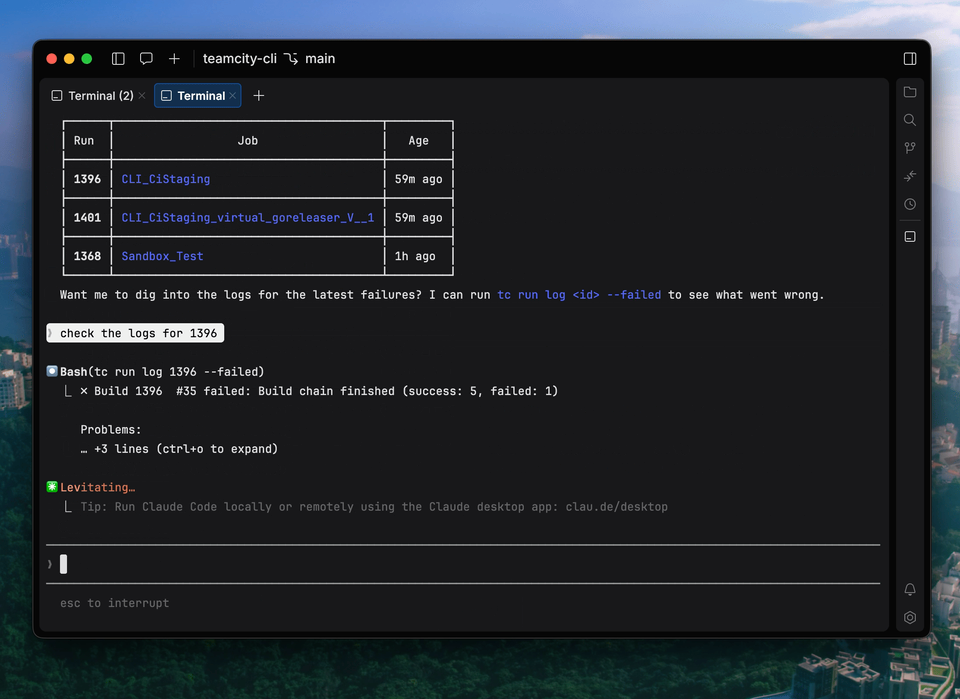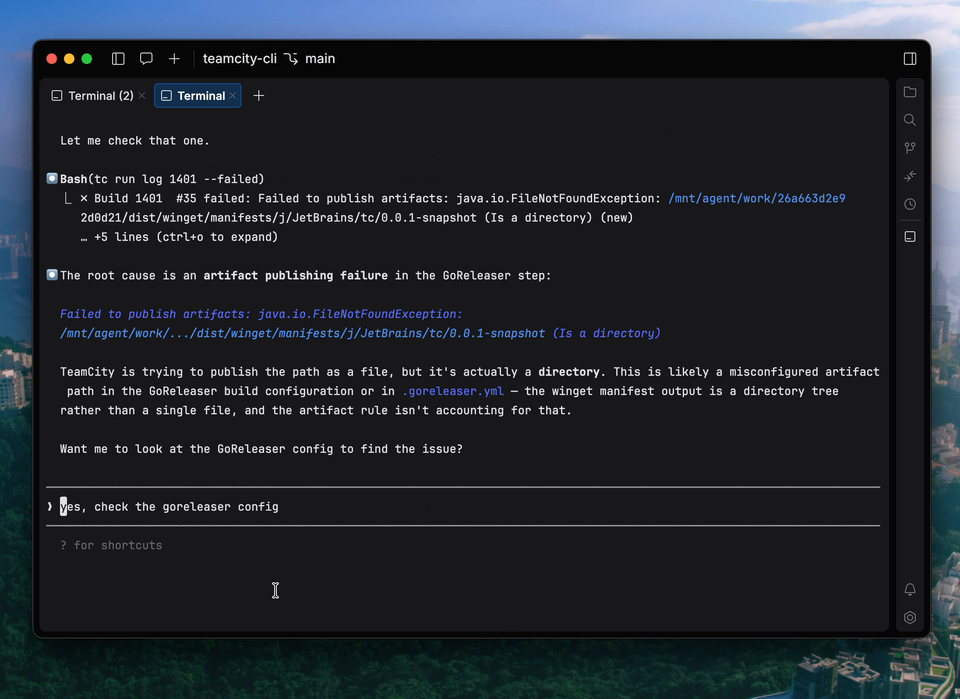
This is a submission for the OpenClaw Writing Challenge
The PC came from my daughter. She was getting a new one … this was going in the trash. 16GB of RAM, a GPU, and the best part? It sounds like a rocket ship whenever I open Chrome. I’d been a Mac guy forever. The thought of using a Windows machine made my skin crawl. But the PC was free, so I took it. Within the hours of setting it up, I downloaded OpenClaw. Within the first fifteen minutes I saw the black screen of death. Not blue … black. I’d heard of the blue screen. Apparently the new thing is black. Maybe I was right all this time.
Everyone said get a Mac Mini. You for sure want the local model for privacy. So I looked. The M4 Pro starts at $1,399 with 24GB unified memory … enough to run models. My friends bought them, created LLCs, wrote off the hardware as CapEx. Good for them.
I wasn’t ready to drop fourteen hundred bucks.
The thing is … I’m not against spending money on tools. I’m against spending my money.
The $40 Discovery
I was determined to find another solution. AWS is my bread and butter. It’s my go-to. When I need cloud infrastructure, I don’t think about Azure or Google Cloud. I think about AWS.
I went that route first. Asked other people using OpenClaw what specs I’d need, then looked up AWS pricing based on those specs. Came back with the price .. and wanted to throw up.
So … I did what we all do. Asked ChatGPT. Asked Claude. Both acted like they never heard of OpenClaw. It must be their distant cousin they pretend not to know.
So I went to Google. Typed “OpenClaw Cloud Hosting.” Found a YouTube Video by Hostinger. They made it look easy. I didn’t believe it would work based on the specs … but at the end of the day I was like, tag on Ollama cloud and … “I can try it for $40.”
Spun up a KVM 1 instance with 1 vCPU and 4GB RAM, and stumbled into something that’s now running 24/7 on my phone, my laptop, my Slack. The Mac Mini I was supposed to buy sits at $1,399 in my browser history, unwatched.
I guarantee a $20 VPS is not as good as a Mac Mini. The models are obviously not running locally … but it works for me.
The System, Not the Tool
What I have isn’t just “OpenClaw on a VPS.” That’s the headline. The reality is more interesting.
OpenClaw is running on that $20 VPS 24/7. It’s integrated into my daily workflows through Slack and Telegram. I can message it from anywhere … laptop, phone, doesn’t matter. It has access to my content pipeline skills: research, drafting, editing, story management.
The assistant doesn’t write for me. It removes the friction between having a thought and getting it down.
The gap between “I have an idea” and “that idea is captured” has always been the hard part. Not the thinking. Not the editing. The transfer from brain to document.
The gap between “I have an idea” and “that idea is captured” has always been the hard part. Not the thinking. Not the editing. The transfer from brain to document.
OpenClaw bridges that gap. I’m still the strategist. I’m still the editor. I’m still the one with the voice. But I don’t get stuck on blank pages anymore.
The Authenticity Question
Here’s what I see happening with AI and content: people are using it to make up shit. They’re generating posts about experiences they haven’t had, advice they haven’t tested, frameworks they haven’t built. The AI writes it, they publish it, and it sounds … off.
I get why they do it. The content treadmill is brutal. Daily posting is unsustainable without help. But there’s a difference between AI-assisted and AI-generated.
My hundred-story library contains real things that happened to me. OpenClaw helps me structure them, find connections, get unstuck. But the source material is mine. The judgment about what to publish is mine. The voice that lands or doesn’t land is mine.
That’s the part people miss when they outsource the whole thing. AI can amplify what you have. It can’t create what you don’t.
Slack + Telegram integration: Interface from any device
Custom skills: Story library, research assistance, drafting support, LinkedIn optimization
Ollama: Running models on the VPS for specific tasks
The VPS runs quietly. I SSH in whenever I need to. The rest of the time, OpenClaw is just … there. An endpoint I can hit from anywhere. A consistent presence that knows my patterns.
It’s not fancy. It’s reliable. It’s been running for months without me touching it.
It’s not fancy. It’s reliable. It’s been running for months without me touching it.
What OpenClaw Gets Right
I’ve tried a lot of AI tools. What OpenClaw gets right that others don’t:
It’s not trying to be a chatbot
It’s trying to be an assistant … something with memory, with skills, with integration into your actual life. The skill system means you can teach it what you need, not just prompt it differently.
It lives where you want
Local if you want. VPS if you want. The abstraction is portable. You’re not locked into someone else’s infrastructure.
It’s built for builders
The people who made OpenClaw seem to understand that the value isn’t in the model … it’s in the system around the model. The orchestration. The memory. The integration.
What This Means For You
If you’re reading this and thinking about personal AI, ask yourself what you’re optimizing for.
Privacy? A VPS on a reputable host is private enough for most workflows. Your threat model may differ.
Speed? Local wins on latency, but only if your hardware is good. My daughter’s old PC with Intel graphics was slower than the VPS.
Cost? $40/month vs $1,400 upfront is math you can do.
Control? OpenClaw gives you plenty. It’s open. You own your data. You’re not locked into anyone’s ecosystem.
The point isn’t that my setup is better. The point is that “local AI” became a default answer before people asked what problem they were actually solving.
The Real Win
I was already writing daily. I’d been using Claude for that. But I’m on the Pro plan, and I was running into my weekly limit with the number of things I was asking it to do.
With OpenClaw and Ollama, I’ve never hit my rolling window. The assistant is always there. I can message it without counting tokens or watching a progress bar. It removes the friction between having something to say and getting it said.
My story library has 100+ entries. I add to it weekly. The assistant helps me find patterns, structure arguments, and get unstuck. But the stories are mine. The voice is mine. The judgment about what goes out is mine.
That’s the system. Not the Mac Mini. Not the VPS. The system of having source material, a process, and an assistant that removes friction instead of adding it.
You don’t need $1,400 to get started. You need a clear sense of what you’re trying to solve … and the willingness to build around your constraints instead of someone else’s recommendation.
The Mac Mini I was supposed to buy sits at $1,399 in my browser history, unwatched. I don’t need it. OpenClaw on a $20 VPS + Ollama pro at $20 is the right abstraction for my wiring.
If you’re building something similar with OpenClaw, I’m curious about your setup. Drop a comment or find me on LinkedIn. I’m always interested in how people solve the same problem with different constraints.
AI is accelerating coding, but without the right checks, it can also introduce risk, inconsistency, and hidden issues into your codebase. Businesses are offering “total automation” and “AI-driven checks” while consumers lose control of code quality and security.
In this livestream, we’ll show how to take control of AI-generated code by bringing deterministic, repeatable quality checks into your CI pipeline.
You’re invited!
Save Your Seat
Join JetBrains experts Kai (Product Specialist, Qodana), Alex (Solutions Engineer, Qodana), and Artem (Solutions Engineer, TeamCity) as they demonstrate how Qodana and TeamCity work together to:
Automatically analyze AI-generated code in CI.
Enforce consistent quality standards with deterministic inspections.
Reduce review bottlenecks and improve developer confidence.
Catch issues before they reach production.
We’ll also run a live demo, showing how AI-generated code flows through a CI pipeline and how Qodana applies reliable, repeatable checks to keep your codebase clean and maintainable.
Whether you’re experimenting with AI-assisted development or already using it in production, this session will help you build workflows that are both fast and trustworthy.
Your speakers
Kai Schmithuesen
Kai is an accomplished product specialist with over 15 years of experience in software sales, focusing on developer tools and practices. Originally from Germany, Kai spent over 17 years living and working abroad, working for international software companies before returning to Berlin.
Also from Qodana…
Alex Costa, Solutions Engineer at Qodana
Alex has spent over a decade helping teams implement modern code quality workflows, working closely with clients to provide live demos and building tailored proofs of concepts and custom solutions. Outside of work, he has a merry band of kids and enjoys crafting handmade dice – a creative outlet that reflects his attention to detail and love of building things from scratch.
From TeamCity…
Artem Rokhin, Solutions Engineer at TeamCity
Artem started out at JetBrains as a release manager over a decade ago and is now based in the Netherlands. As a certified JetBrains and TeamCity expert, he helps teams automate their CI/CD pipelines so every code change is built, tested, and validated before reaching production. He works closely with developer advocates and the developer community, putting his master’s degree in technology to good use.
Everyone had their lane. Everyone had their process. Everyone had their artifact.
And everyone also had a favorite way to say, “That’s not really my job.”
Then AI showed up and quietly started wrecking that neat arrangement.
Not because roles disappear overnight.
Not because everyone suddenly becomes a full-stack polymath with suspiciously good taste.
But because AI changes the economics of turning ideas into product.
And once that happens, the highest-leverage people in the room are no longer the ones with the cleanest job title.
They’re the ones who can move fastest across the boundary between idea and reality.
At a big company, that often means one thing:
The most dangerous designer is the one who can ship
The old model was built around handoff.
A designer produced flows, mocks, prototypes, and specs. Then engineering took over and translated intent into production reality.
That model was never perfect, but it worked well enough when the cost of building was high and the cost of iteration was slow.
AI changes that.
It lowers the cost of exploration.
It lowers the cost of implementation.
It lowers the cost of trying multiple directions before committing.
So the bottleneck moves.
The bottleneck is no longer just, “Can we make this?”
It becomes:
Can we ideate fast enough?
Can we test fast enough?
Can we get the right thing into production before momentum dies?
Can we preserve quality while speeding everything up?
That first question matters more than people think.
A lot of life and work advantage now lies in the ability to ideate quickly.
Not just to have ideas.
To make them tangible while they are still alive.
That is the real leverage.
At big companies, plenty of people can talk about an idea in a meeting.
Far fewer can turn a half-formed intuition into a believable interaction, pressure-test it, and ship a version before the org metabolizes it into a calendar invite.
That is where role boundaries start to blur.
In B2B products, the speed of turning insight into production matters more than people admit
This is especially true in B2B.
Consumer products get celebrated for delight. B2B products live or die on workflow.
A slightly better onboarding flow can improve activation.
A cleaner approval experience can reduce operational error.
A smarter default can save hundreds of hours across teams.
A better AI-assisted workflow can be the difference between adoption and shelfware.
A lot of these improvements die in the handoff gap.
The designer sees the problem.
The mockup captures the idea.
The team agrees it is promising.
Then it enters the queue, competes with everything else, gets translated imperfectly, and loses half its sharpness before it reaches production.
If a designer can code well enough to close some of that gap, the equation changes.
Now they can:
prototype at higher fidelity
test interaction details static mocks cannot capture
validate whether a workflow actually feels better
preserve the original product intuition
ship improvements faster and learn faster
In B2B, that matters a lot.
Because product quality in B2B is often not about visual polish alone. It is about whether the workflow actually works under pressure.
When a designer can move quickly from insight to code to production, the company learns faster.
And in B2B, learning faster often matters more than presenting prettier slides about learning faster.
The same thing is happening in consumer products, just with different stakes
In consumer, the stakes look different, but the pattern is the same.
The value is not only in shipping features faster. It is in ideating on experience faster.
Imagine a team working on a music app, shopping app, or social product. The winning idea is often not a giant feature. It is a tiny behavior:
how recommendations enter the screen
how a creation flow nudges you forward
how an AI assistant feels helpful without feeling clingy
how a moment of surprise becomes delight instead of interruption
Those things are incredibly hard to evaluate in static mocks.
A static design might tell you what the screen looks like.
It usually does not tell you whether the experience has any life in it.
If a designer can code, they can prototype these moments much closer to reality.
They can test timing, animation, responsiveness, and behavioral nuance before the team burns weeks aligning on something that only looked convincing in Figma at 2x zoom.
That matters because consumer advantage increasingly lives in the speed of ideation.
The teams that win are often the ones that can try five experience directions while everyone else is still debating which one deserves a ticket.
In B2B, fast ideation improves workflows.
In consumer, fast ideation improves feel.
In both cases, the leverage comes from shrinking the distance between taste and reality.
Code is becoming a design material
This is the shift many people still underestimate.
Code is no longer just an implementation medium. It is increasingly a design material.
Not for every designer. Not in every situation. But especially in AI products, code unlocks forms of prototyping that are much closer to real product behavior.
A static mock will not tell you:
whether the suggestion arrives at the right moment
whether the user trusts the output
whether the transition feels assistive or intrusive
whether confidence levels are legible
whether the interaction feels magical or just noisy
If you want to design delightful AI experiences, you often need to prototype behavior, not just layout.
And behavior lives much closer to code than to Figma.
A coded prototype lets you explore timing, motion, responsiveness, uncertainty, progressive disclosure, and how human input and machine output actually dance together.
That is where delight starts to become real.
Not in the mock.
In the interaction.
This is starting to look less like product design and more like architecture
The closest analogy I keep coming back to is architecture.
Architects are not expected to personally pour the concrete, run every project meeting, calculate every structural load, and fabricate every material.
But they are expected to understand the whole building.
They are expected to know enough across structure, systems, constraints, sequencing, and experience to be responsible for the design end to end.
They work with partners: project managers, structural engineers, contractors, specialists.
But nobody says, “Well, the architect only chose the wallpaper, the rest is someone else’s problem.”
That would be insane.
And yet in product, we somehow accepted a version of that for years.
We created a world where a designer could be seen as responsible for screens but not behavior, responsible for intent but not implementation, responsible for the mock but not whether the thing actually survives contact with production.
That model is getting weaker.
The new expectation is not that designers must do every job.
It is that the strongest ones increasingly understand enough of the full system to move ideas through it.
That is a very architectural kind of responsibility.
The role is changing faster than the org chart
I do not think we are heading toward a future where everyone has one stable, perfectly defined role.
I think we are heading into a messier period where product work becomes an array of skills rather than a set of rigid titles.
Some designers will become stronger at prototyping.
Some engineers will become stronger at product thinking.
Some PMs will get better at making things.
Some researchers will become more embedded in faster iteration loops.
In the short term, this feels chaotic.
It can feel threatening because the old map stops working.
But this kind of fragmentation is not new. It is what happens before a new order forms.
There is a line from Romance of the Three Kingdoms that captures this well:
What has long been divided must unite; what has long been united must divide.
That is what this moment feels like in product building.
For a long time, product roles split into increasingly specialized functions. Now AI is pushing them back together in certain places.
Design and code are converging.
Prototyping and production are getting closer.
Strategy and execution are collapsing into faster loops.
Later, new patterns will emerge. New specializations will form. New titles will probably appear.
But right now, we are in the messy middle.
And in the messy middle, people with range win.
What big companies should pay attention to
The companies that benefit most from this shift will not be the ones that merely adopt AI tools.
They will be the ones that recognize a deeper organizational change: the distance between thinking and shipping is shrinking.
If that is true, then the highest-leverage people are the ones who can compress that distance.
That means big companies should pay more attention to people who can:
move from concept to prototype to production with minimal loss of intent
use code to explore experience, not just implement requirements
ideate quickly and make ideas testable before they go stale
combine taste, product judgment, and technical fluency
These people may not fit the old boxes cleanly.
That is fine.
The old boxes are part of the problem.
My bet
My bet is that the next generation of standout product people in large companies will not be defined by title first.
They will be defined by leverage.
Not designer.
Not engineer.
Not PM.
But something closer to this:
Can they see the opportunity?
Can they make it tangible?
Can they test it in reality?
Can they get it into production?
Can they create something users actually feel?
The org chart will take time to catch up.
But the work is already changing.
And in this new environment, the people who can design, code, prototype, and ship are not breaking the system.
They are showing us what the next system looks like.
About Me
I’m Ling Zhou, a Staff Product Designer at Uber, passionate about delivering magical user experiences. Based in Chicago, I’m a former creative and indie filmmaker turned designer. I’m also a proud mom to a curious 5-year-old boy and a goofy 6-year-old Bernese mountain dog. Excellent on a bike, less so behind the wheel. Lover of books, aspiring fiction writer, and endlessly interested in how AI, design, and product building collide in real life.
Your Virtual Threads Are Leaking: Why ScopedValue is the Only Way Forward.
If you’re spinning up millions of Virtual Threads but still clinging to ThreadLocal, you’re building a memory bomb. Java 21 changed the game, and if you haven’t migrated to ScopedValue yet, you’re missing the actual point of lightweight concurrency.
Why Most Developers Get This Wrong
The Scalability Trap: Treating Virtual Threads like Platform Threads. Thinking millions of ThreadLocal maps won’t wreck your heap is a rookie mistake; the per-thread overhead adds up fast when you scale to 100k+ concurrent tasks.
The Mutability Nightmare: Using ThreadLocal.set() creates unpredictable side effects in deep call stacks. In a world of massive concurrency, mutable global state is a debugging death sentence.
Manual Cleanup Failures: Relying on try-finally to .remove() locals. It inevitably fails during unhandled exceptions or complex async handoffs, leading to “ghost” data bleeding between requests.
The Right Way
Shift from long-lived, mutable thread-bound state to scoped, immutable context propagation.
Use ScopedValue.where(...) to define strict, readable boundaries for your data (like Tenant IDs or User principals).
Embrace Structured Concurrency: use StructuredTaskScope to ensure context propagates automatically and safely to child threads.
Treat context as strictly immutable; if you need to change a value, you re-bind it in a nested scope rather than mutating the current one.
Optimize for memory: ScopedValue is designed to be lightweight, often stored in a single internal array rather than a complex hash map.
Show Me The Code
privatefinalstaticScopedValue<String>TENANT_ID=ScopedValue.newInstance();publicvoidserveRequest(Stringtenant,Runnablelogic){// Context is bound to this scope and its children onlyScopedValue.where(TENANT_ID,tenant).run(()->{performBusinessLogic();});// Outside this block, TENANT_ID is automatically cleared}voidperformBusinessLogic(){// O(1) access, no risk of memory leaks, completely immutableStringcurrentTenant=TENANT_ID.get();System.out.println("Working for: "+currentTenant);}
Key Takeaways
Memory Efficiency:ScopedValue eliminates the heavy ThreadLocalMap overhead, making it the only viable choice for high-density Virtual Thread architectures.
Safety by Default: Immutability isn’t a limitation; it’s a feature that prevents “spooky action at a distance” across your call stack.
Structured Inheritance: Unlike InheritableThreadLocal, which performs expensive data copying, ScopedValue shares data efficiently with child threads within a StructuredTaskScope.
Want to go deeper? javalld.com — machine coding interview problems with working Java code and full execution traces.
Last year Amazon shipped Vega, a brand new operating system, with hundreds of apps already live on the platform.
How did that happen, so many apps already live and performant on launch day?
And what was that like, building for a platform while it’s still being built? Like aiming for a moving target from atop a moving vehicle.
I helped host a Vega meetup in Munich and three devs were generous enough to share their from-the-trenches perspectives on this unique challenge.
Sebastian Mader, a senior smart TV developer at ProSieben, shares his journey bringing Joyn, the free ad-supported streaming service, to Vega. After his team’s previous project was cancelled in March 2023, his team got their hands on a strange Fire TV stick in April, kicked off development in June on SDK version 0.4, and spent the following months watching each new SDK update break their app. The core lesson: React Native on Vega is not React.js, and when performance matters, sometimes the right move is to pull code out of React entirely. He walks through how the team rewrote Joyn’s player as a plain TypeScript controller with a view-model bridge, cutting startup time by 50%.
Artur Morys-Magiera, a senior React Native engineer at Callstack, discusses the pitfalls of developing on a new, performance-sensitive platform. He walks through a five-step methodology: define, measure, analyze, improve, control. He also discusses the tooling landscape: Reassure for catching performance regressions in CI, OpenTelemetry, Embrace, and Sentry for production monitoring, Flashlight and React DevTools for dev-time inspection, and Callstack’s own Ottrelite library for tracing across JavaScript, C++, Kotlin, and Swift.
Matthias Fesich, an iOS-turned-React-Native developer at DNA inc., shares his team’s 18-month journey porting an existing audio/video streaming app onto Vega. Starting in January 2024 with just three developers, they took a codebase already shipping on iOS, Android, and web and rebuilt it in React Native for Vega, landing four to five weeks ahead of deadline. He discusses the three principles that kept the team moving while the platform kept shifting underneath them: move fast without breaking things, reuse code and logic from the sister apps, and anticipate change.
We also got a bonus talk from Christian Van Boven, Principal Product Manager at Amazon, who shares the upcoming roadmap for Vega:
Some details have changed since the talk, but it’s still the best overview of where Vega is heading in 2026.
Two years ago, if you asked an AI to design a menu for a Mexican restaurant, you’d get a beautiful layout of “enchuita” and “churiros.” It looked like food, and the font looked like letters, but it was essentially a visual fever dream. The “burrto” became a classic meme in dev circles — a reminder that while AI could paint like Caravaggio, it had the literacy of a toddler.
Yesterday, OpenAI launched ChatGPT Images 2.0 (gpt-image-2). I ran the same test. The menu was perfect. Not just the spelling, but the hierarchy, the prices, and the specialized diacritics. It is no longer just “generating pixels.” It is communicating.
This isn’t a minor version bump or a better training set. It’s a total architectural pivot that signals the end of an era. If you’ve spent the last three years building workflows around diffusion models, it’s time to rethink your pipeline.
1. Why text was broken (and how they fixed it)
To understand why gpt-image-2 works, you have to understand why DALL-E 3 failed at spelling. Diffusion models — the tech behind almost every major generator until now — work by denoising. They start with static and try to “find” an image. Because text pixels make up a tiny fraction of a training image, the model learned the texture of text rather than the logic of characters. To a diffusion model, an “A” is just a specific arrangement of lines, not a semantic unit.
OpenAI has quietly abandoned diffusion. While they won’t officially confirm the guts of the system, the PNG metadata and the model’s behavior tell the story: this is an autoregressive model.
It generates images the same way GPT-4 generates code — by predicting the next token. By integrating image generation directly into the language model pipeline, the model isn’t “drawing” a word; it’s “writing” an image. When the architecture treats a pixel and a letter as parts of the same conceptual stream, the “enchuita” problem simply vanishes.
2. The end of the CSS overlay hack
For those of us in agency work or product dev, AI images have always been a “background only” tool. If a client wanted a marketing banner with a specific CTA, we’d generate the art, then use a graphics library or CSS to overlay the text. It was the only way to ensure the brand name wasn’t spelled “Gooogle.”
Gpt-image-2 changes that calculus. With near-perfect rendering of Latin, Kanji, and Hindi scripts, the “post-processing” stage of the workflow is suddenly on the chopping block. You can now generate multi-paneled assets or social media posts where the text is baked into the composition with proper lighting and perspective.
But there’s a catch for your budget. At approximately $0.21 per high-quality 1024×1024 render, this is roughly 60% more expensive than the previous generation. If you’re at a high-volume startup, that’s a significant line item.
3. Thinking before rendering
The most impressive part of the new model isn’t the resolution — it’s the “thinking mode.” Borrowed from reasoning models like o3, the generator now spends compute time planning the layout before it touches a single pixel.
I watched it handle a prompt for “a grid of six distinct objects, each with a label in a different language.” Previous models would lose count by object four and turn the labels into Sanskrit-flavored gibberish. Gpt-image-2 paused, “thought” (generating reasoning tokens), and then executed. It can count. It can follow layout constraints.
This moves AI generation from “creative toy” to “reliable infrastructure.” Reliability is what we actually need in production. I’d much rather pay more for a single correct image than spend credits on ten “cheap” re-rolls.
4. The DALL-E eulogy
OpenAI is shutting down DALL-E 2 and 3 on May 12, 2026. Not moving them to a legacy tier — shutting them down.
This is a massive signal. It’s an admission that the diffusion approach hit a ceiling that no amount of fine-tuning could break. By retiring the DALL-E brand in favor of a unified ChatGPT Image model, OpenAI is betting that the future of Multimodality is a single, unified architecture.
The wall between “thinking” and “seeing” is being torn down. We used to have a brain (LLM) that sent instructions to a hand (Diffusion model). Now, the brain is doing the drawing itself.
5. What I’m still worried about
Despite the polish, there are gaps. The knowledge cutoff is December 2025. If you need a render involving a trend or news event from early 2026, you’re reliant on the web search tool, which adds latency and even more cost.
Furthermore, the pricing model is now “tokenized” for images. Thinking mode adds a variable cost based on how many reasoning tokens the model uses to plan the composition. This makes it incredibly hard to predict API costs for complex apps. You aren’t just paying for an image; you’re paying for the “brain power” required to frame it.
6. The 2026 reality check
If you are building a simple placeholder tool, stick to cheaper, older models. But for any workflow where the image is the content — marketing, UI prototyping, or localized assets — the shift to autoregressive generation is a one-way door.
We’re entering a phase where the term “image model” feels dated. We just have models. They happen to output pixels sometimes and Python code others. The fact that it can finally spell “Burrito” is just the first sign that the gap between human intent and machine execution has finally closed.
I’ve been working on this idea called WinToLin, the goal is to make the switch from Windows to Linux as simple as possible.
The steps are:
You go trough the steps in the tool on Windows.
-You select the apps and files you care about.
It creates a bootable USB.
You boot from it and it automatically installs and sets up your selected Linux distro that matches your previous setup as closely as possible
Right now this is still very early and mostly an experiment.
Only basic parts exist and only Ubuntu is supported so far.
I’d really appreciate feedback on things like:
What would be the hardest part of switching for you?
What would absolutely need to work for you to even consider using something like this?
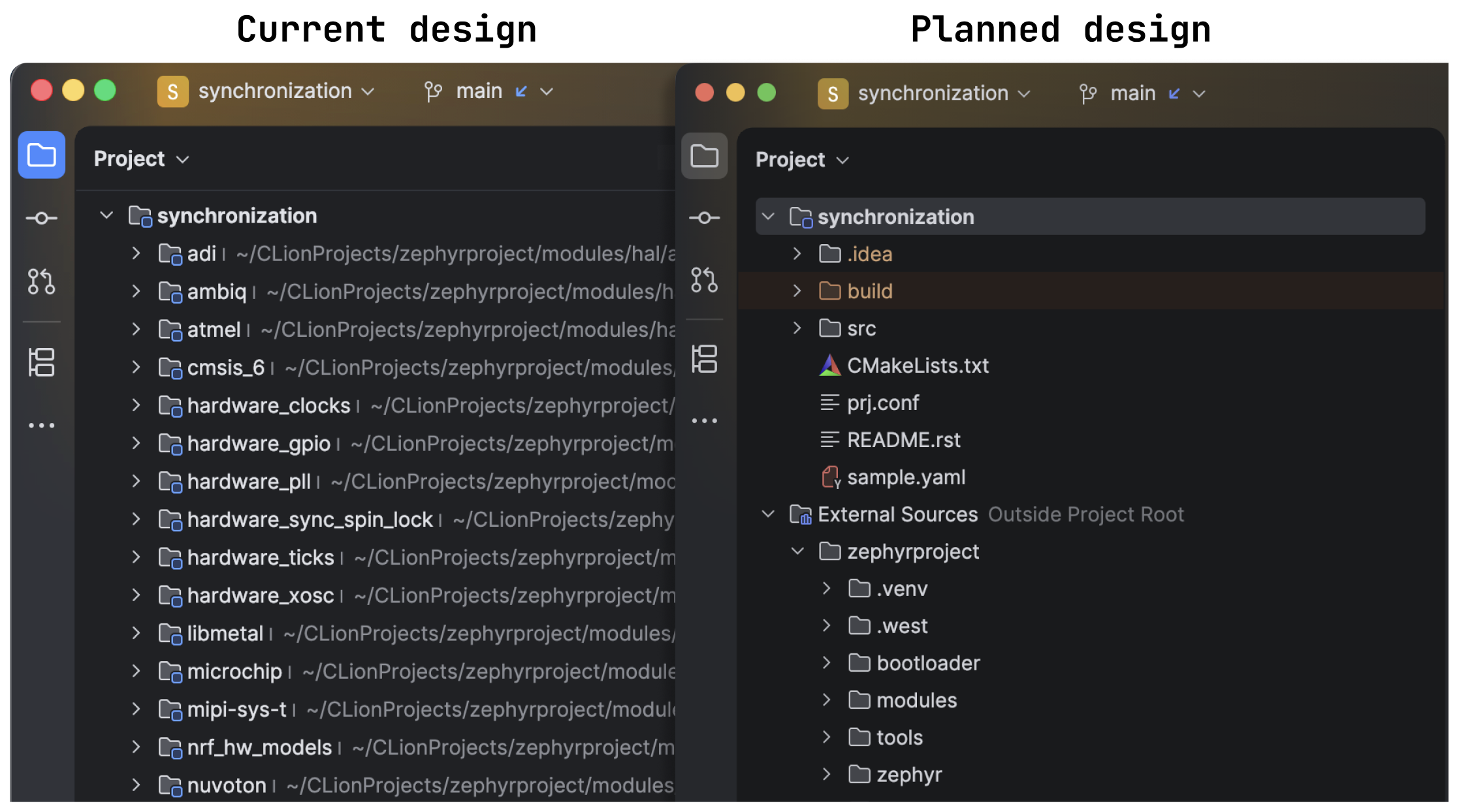
We’ve begun work on our next major release, version 2026.2, which we plan to introduce in a few months. After reviewing your feedback and our strategic goals, we’ve decided to focus on improving build tools, including Bazel, as well as project formats, the embedded experience, and the debugger. Here are our more specific priorities:
Simplified debugger configuration.
Support for using multiple Zephyr West profiles.
Easier inspection of fields and global variables in the debugger.
Better UI for external sources in the Project tool window.
Read on to learn more about the updates we have planned.
Our team is committed to creating an IDE that makes development smooth and productive. However, the following is only a preliminary roadmap. We can’t guarantee that all issues and features listed below will be addressed or implemented in CLion 2026.2. Unexpected circumstances could require us to change our plans or implementation timelines for some items.
Debugger
The upcoming release will bring a unified configuration workflow, a more flexible variable inspection experience, and the ability to assign breakpoints to specific debug configurations.
Simplified debugger configuration
Currently, there is no simple way to configure the debugger – you have to deal with different settings: Toolchains, Run/Debug Configuration, Debug Servers, and sometimes DAP Debuggers. This gets even more complicated for embedded projects.
In the next release, we plan to introduce a new settings section, tentatively called Debug Profile, that provides a single, unified place to configure all your debugging setups – local, remote, and embedded. Whether you’re using GDB, LLDB, SEGGER J-Link, or ST-Link, everything will live in one place, significantly simplifying the debugger configuration process.
Help us ensure the debugger offers a UX that works for you by participating in this survey.
Easier inspection of fields and global variables
When inspecting a suspended program during debugging, only local variables are automatically tracked and displayed in the Threads & Variables pane. To see fields (class member variables) or global variables used in functions, you need to set up watches for them. However, for some users, fields or global variables may be just as important as local ones, and automatically adding them to the variable list would reduce manual work.
To accommodate this workflow, we’re adding a new option in the Debugger settings. It will allow the debugger to automatically display fields and global variables in the Threads & Variables pane, while still keeping them distinct from local variables. We plan to introduce this in one of the upcoming EAP builds and would love to get your feedback once it’s available (CPP-4992).
Configuration-specific breakpoints
CLion lets you run multiple debug sessions, either sequentially or in parallel. Currently, breakpoints are global, so you cannot assign them to a specific debug configuration. This can be a limitation when debugging multi-process systems or multiple tests. We plan to add configuration-specific breakpoints in the next release (CPP-34455).
Build tools and project formats
In 2026.2, we’ll deliver a range of updates to build tools and project formats, including a better Project tool window experience for external sources, a refactoring to make it easier to rename CMake targets, expanded Bazel plugin support, and updated bundled toolchains.
Better UI for external sources in the Project tool window
When working with source files or folders outside of your root project, the IDE displays them in the same folder as your root project sources in the Project tool window. This works fine if all the sources have unique names. However, when external sources share names with project root sources and their paths are long, it can be difficult to distinguish between them. This is often the case for embedded developers working on projects that require external libraries and files, like Zephyr ones. For the next release, we plan to add a separate node to group all external sources, making it easier to distinguish them from internal sources.
Easier CMake target renaming
CMake targets are executables, libraries, and utilities created with commands such as add_executable or add_library. Currently, when you need to rename a target in CLion, you have to manually edit all its occurrences. We plan to add a refactoring operation that automatically updates all definitions and usages of a target name across your CMakeLists.txt files.
Improvements to the Bazel for CLion plugin
We plan to expand support for configuration transitions introduced in the previous release:
If you’re using the CLion Nova engine, you’ll be able to switch configurations when multiple exist for the same file (which is currently only possible for CLion Classic users).
The plugin will automatically select the correct configurations when you debug or run a target, ensuring your code insight always reflects the active one.
We also plan to fix the build options inconsistency caused by hardcoded flag injection in the plugin (see the corresponding GitHub issue for more details).
Bundled toolchain updates
We’ll update some tools shipped with CLion, including:
CMake to v4.3
GDB to v17.1
GCC to v15.2.0
Mingw-w64 to v13
CMake 2.8 support will be deprecated.
Embedded development
Embedded developers can look forward to two major improvements in 2026.2: a more flexible way to manage multiple Zephyr West build configurations and extended support for live watches.
Support for using multiple Zephyr West profiles
We want to make it easier to manage multiple West build configurations that have different build parameters or target different boards. To this end, we’ll add the ability to create configuration profiles for Zephyr West projects, similar to CMake profiles (CPP-42799).
Improvements to live watches
With live watches, you can monitor global variables in real time – no need to stop the debugger or interrupt a program’s execution. In the next release, we’ll extend the support for variable types by making it possible to inspect arrays and structs.
Conclusion
The Early Access Program is just around the corner and will give you the chance to try all of the new features planned for the next major release for free. In the meantime, upgrade to CLion 2026.1 if you haven’t already done so, and let us know what you think!
Developers now use AI for nearly everything, except the part that actually ships code.
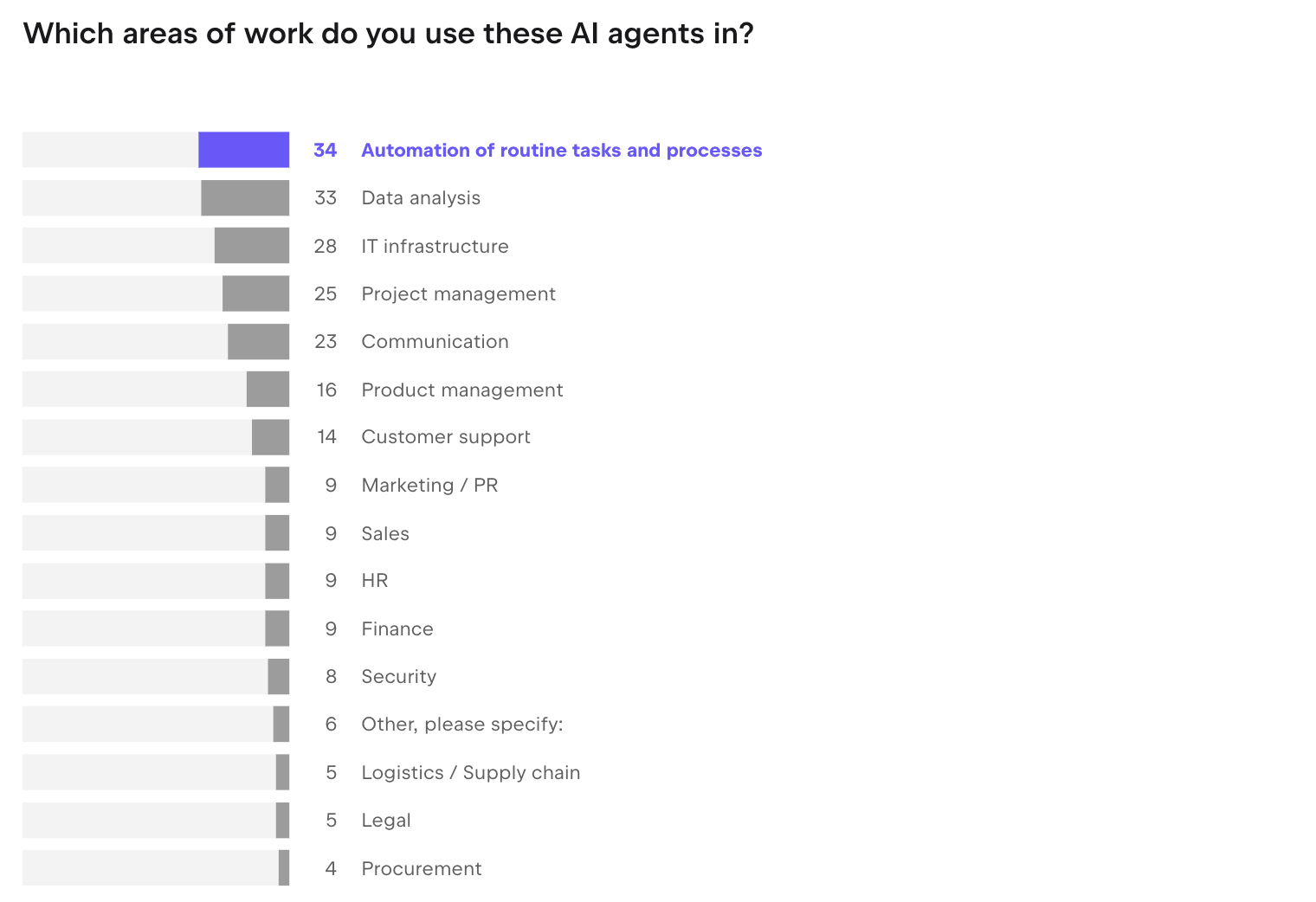
Recent surveys conducted by JetBrains indicate that AI is now widely used in software development, with workplace usage exceeding 90% and a large majority of developers already incorporating it into daily workflows. Developers rely on these tools for writing code, debugging, and navigating unfamiliar systems.
Source: JetBrains AI Pulse, January 2026
However, when you look at CI/CD pipelines, adoption is much more limited. This difference reflects how teams evaluate risk across the delivery lifecycle.
CI/CD pipelines are the stage where changes are validated and prepared for release. At this point, teams rely on consistent, reproducible signals. Introducing non-deterministic systems into this environment raises concerns around reliability, compliance, and production impact.
Note on data: The findings referenced in this article are based on internal JetBrains research conducted in January 2026 (AI Pulse) and October 2025 (State of Developer Ecosystem and State of CI/CD Tools reports). Given the pace of change in AI, these results should be interpreted as a snapshot of current trends rather than a fixed baseline.
Key insight: AI adoption is highest where the cost of mistakes is low. CI/CD operates under different constraints.
How AI is used in software development today
According to JetBrains’ AI Pulse (January 2026), AI tools are now used by a large majority of developers in their daily work, and AI is already embedded in many parts of the software development lifecycle, but its impact is uneven.
In practice, most of the value today is concentrated upstream from CI/CD pipelines, in areas where developers can iterate quickly and validate results informally.
The table below compares how AI is used in day-to-day development work versus AI in DevOps pipelines. Each row highlights one aspect of the workflow and shows how the conditions differ.
Dimension
Upstream (IDE/dev workflow)
CI/CD pipelines
Feedback loop
Immediate and local, results are visible right away
Slower and system-wide, feedback comes from full pipeline runs
Cost of error
Low; changes can be reverted easily
Higher; failures can affect builds or releases
Validation
Informal and often manual
Formal and automated through tests, scans, and checks
Role of AI
Assists developers during coding and exploration
Assists, but outputs must pass strict validation
Adoption level
High; widely used in daily workflows
Limited; used cautiously in specific scenarios
In day-to-day development work, AI is primarily used to accelerate routine tasks. Developers rely on it to generate code, refactor existing logic, and explore unfamiliar APIs. These interactions are fast and low-risk because they are easy to verify locally and can be discarded without consequences.
Source: JetBrains State of Developer Ecosystem 2025
The same applies to debugging workflows, where AI helps interpret logs and suggest likely causes of failures. Even when suggestions are imperfect, they provide a useful starting point that reduces the time spent on manual investigation.
AI is also widely used for documentation and knowledge discovery. In large codebases, understanding existing systems often takes longer than writing new code. AI reduces this friction by summarizing components, explaining dependencies, and surfacing relevant context.
Similarly, in security workflows, AI is increasingly used to flag potential vulnerabilities and suggest fixes, particularly in earlier stages of development.
What unites these use cases is not the specific task, but the environment in which they operate. They all sit in parts of the workflow where feedback is immediate, mistakes are easy to detect, and decisions can be reversed with minimal cost.
CI/CD pipelines operate under different conditions. Changes are no longer local experiments but candidates for release. At this stage, the cost of error increases, and the system relies on consistent, reproducible validation signals.
This shift in constraints explains why AI adoption is not progressing at the same pace across the entire DevOps lifecycle. Generally speaking, AI is expanding more quickly in development workflows and more cautiously inside CI/CD pipelines.
Why AI adoption in CI/CD is still low
AI in DevOps is still at an early stage compared to development workflows.
What the data shows
73% of organizations don’t use AI in CI/CD pipelines at all
60% cite unclear use cases or value
36% cite lack of trust in AI-generated results
33% cite data privacy concerns
Source: JetBrains State of CI/CD Tools survey
These results suggest that the main challenge is not technical integration. Teams are evaluating whether AI can reliably and predictably deliver value within a system that is responsible for validation.
In practice, AI adoption inside pipelines is shaped more by trust and measurable outcomes than by model capability.
Source: JetBrains State of CI/CD Tools survey
CI/CD is an evidence system, not just automation
CI/CD is often framed as automation, but that undersells what it actually does. Its real job is to give teams enough confidence to ship changes without fear.
Every step in a pipeline is designed to reduce the likelihood and impact of production failures. Builds confirm code compiles. Tests validate behavior. Deployment processes ensure changes can go out and come back cleanly.
Think of it this way: CI/CD turns code changes into signals teams can act on. Test results, logs, deployment outcomes, all these answer one question: is this safe to release?
AI complicates this. It increases both the volume and variability of changes entering the pipeline, and CI/CD is built around predictability. That results in tension.
But it’s not a compatibility problem. AI-generated changes can move through a pipeline the same as any other, provided the pipeline can validate them with enough confidence. What changes is the stakes. When code is being written faster and in larger quantities, having a system that can catch bad changes reliably matters more, not less.
Where AI actually works in CI/CD today
Current use of AI in CI/CD pipelines is focused on improving how evidence is generated and interpreted.
Failure diagnosis
AI is most effective in CI/CD when it is used to speed up failure analysis rather than to make decisions. By processing pipeline logs at scale, identifying recurring patterns, and correlating errors across runs, AI tools help engineers identify likely root causes much faster than manual inspection.
This reduces initial triage time and allows teams to focus on resolving issues, while keeping decisions firmly under human control.
TeamCity CLI and Claude Code analyzing what builds are failing
In practice, this reduces the time spent on initial triage and allows teams to focus on resolving issues, while keeping the decision-making process firmly under human control.
Security fixes
In security workflows, AI is increasingly used to assist with identifying and remediating vulnerabilities discovered during pipeline execution. Rather than replacing existing scanning tools, AI builds on top of them by interpreting findings, suggesting fixes, and in some cases generating patches.
These suggestions still pass through standard CI/CD validation steps, including testing and review, which ensures that security improvements do not introduce regressions or unintended side effects.
Test optimization
Testing remains one of the most resource-intensive parts of CI/CD, and this is where AI is beginning to show measurable impact. By analyzing historical test runs and code changes, AI can prioritize which tests are most relevant for a given change, identify patterns of flaky behavior, and reduce redundant execution.
This leads to faster pipelines and more relevant feedback without sacrificing coverage entirely. Faster feedback is valuable, but it only matters if teams can still trust the results.
In practice, this means treating AI-driven test selection as an optimization layer rather than a replacement for validation. Teams often keep periodic full test runs in place and monitor for defects that might slip through reduced test sets. This approach allows them to increase speed without weakening the pipeline’s reliability.
The common thread across these use cases: AI is making validation more efficient, not replacing it.
From copilots to agents: What’s changing
The role of AI in DevOps is evolving from assistance to participation in workflows. Early tools focused on suggesting code or helping developers understand unfamiliar parts of the codebase by explaining logic, tracing dependencies, and summarizing large components.
Newer systems are beginning to generate changes, propose pull requests, and iterate based on feedback.
This shift introduces a different interaction model. Instead of developers being the only source of change, AI systems become contributors that operate within repository and pipeline workflows. They can suggest modifications, open pull requests, and respond to feedback loops created by CI/CD pipelines.
At first glance, this can create the impression that AI and CI/CD are in conflict. AI introduces more change, more variability, and less predictability, while CI/CD exists to enforce stability and control.
In practice, the opposite is true. The more AI participates in generating changes, the more teams rely on CI/CD to evaluate and constrain those changes. Pipelines become the mechanism that determines which AI-generated outputs are acceptable and which are not.
💡 Read also: How We Taught AI Agents to See the Bigger Picture
The implication for CI/CD is significant. Pipelines are no longer validating only human-written code. They are increasingly responsible for evaluating changes produced by automated systems. CI/CD becomes the environment where AI-generated changes are tested, constrained, and approved before they reach production.
In practical terms, this means AI in DevOps moves from being a productivity layer in the IDE to becoming part of the delivery system itself. The quality of that system determines whether agent-driven workflows can be adopted safely.
The maturity model of AI in CI/CD
AI doesn’t enter CI/CD all at once. Teams move through it gradually, expanding what they trust AI to do as the system proves itself.
Most teams are still at the starting point: AI isn’t in the pipeline at all. Developers might use it heavily in their editors, but the pipeline itself treats every change the same, regardless of how it was written.
The first real integration is usually about failure analysis. When a pipeline breaks, AI can read the logs, identify the error, and suggest what likely caused it. Engineers still make the call on what to fix and how. AI just cuts down the time spent staring at output trying to figure out where things went wrong.
From there, teams start letting AI generate outputs: suggested fixes, pull requests, configuration changes, test improvements. These still go through normal review and validation. AI is part of the workflow, but a human is still deciding what ships.
AI is part of the workflow, but a human is still deciding what ships
The furthest stage is agent-like behavior, where AI can trigger actions on its own: opening pull requests, rerunning pipelines, proposing changes without being asked.
This doesn’t mean AI acts without limits. It can only trigger actions that have been explicitly permitted, every action is logged, and anything significant still requires a human to approve it before it goes through.
What determines how far a team can go with AI in CI/CD is whether the surrounding system, the validation, the policies, the pipeline signals, is reliable enough to support it.
Most teams are still in the first two stages, and survey data backs that up: direct AI integration inside CI/CD workflows remains uncommon. According to the JetBrains AI Pulse, 78.2% of respondents don’t use AI in CI/CD workflows at all.
What matters across these stages is not the sophistication of the models, but the level of trust in the surrounding system. Each step forward requires stronger validation, clearer policies, and more reliable signals from the pipeline.
Most teams today remain in the first two stages, where AI is used to support understanding rather than to execute changes. This aligns with broader survey data showing limited adoption of AI directly inside CI/CD workflows.
To summarize this progression, the stages can be viewed side by side:
Stage
What changes in practice
Level of control
No AI
Pipelines treat all changes equally
Fully human-driven
AI-assisted understanding
AI explains failures and logs
Human decisions
AI-assisted proposals
AI suggests fixes, PRs, and test changes
Human review required
Agentic workflows
AI can trigger actions within pipelines
Governed and constrained
This framing highlights that adoption is not about adding AI features, but about increasing the level of trust a team is willing to place in automated decisions.
What this means for CI/CD systems
As AI becomes more embedded in development workflows, the role of CI/CD systems shifts from automation to control and validation.
Three areas become critical:
First, the reliability and clarity of pipeline results start to limit how effectively teams can use AI. AI increases the volume of changes entering the system, which puts pressure on testing, build stability, and signal reliability. Flaky tests, inconsistent builds, and unclear feedback loops become more visible and more costly.
Second, pipelines need clear controls over how changes progress. As AI systems begin to propose or trigger changes, teams rely on approvals, policy checks, access controls, and audit trails to govern them. These controls already exist in CI/CD, but they become more central as automation increases.
Third, integration with external systems becomes more important. CI/CD platforms are increasingly expected to expose pipelines, logs, and workflows in a way that other tools, including AI systems, can interact with. This shifts CI/CD from a closed automation system to a component in a broader toolchain.
Conclusion: AI in DevOps needs a trust layer
AI is accelerating software development workflows. CI/CD systems continue to focus on validation and release readiness. These two facts are not in conflict, but they do create pressure.
As AI-generated changes become more common, the role of CI/CD becomes more critical in ensuring those changes meet the standards required for production. Teams will increasingly evaluate their delivery systems based on their ability to handle higher change volume while maintaining reliability.
But the questions the industry has not fully answered yet are the following: As AI agents become more capable and more autonomous, how do you build governance mechanisms that scale with them? What does meaningful human oversight look like when a pipeline is processing hundreds of AI-generated changes per day? And at what point does the evidence that CI/CD produces need to be audited by AI itself?
These are not hypothetical. They are the questions that will define how CI/CD evolves over the next few years.
IntelliJ IDEA 2026.1.1 has arrived with several valuable fixes.
You can update to this version from inside the IDE, using the Toolbox App, or using snaps if you are a Ubuntu user. You can also download it from our website.
Here are the most notable updates included in this version:
It’s once again possible to set up a WSL Python SDK. [IJPL-240728]
Emmet in remote development now works as expected. [IJPL-168255]
Gradle sync no longer fails due to a class cast error involving InternalIdeaModule and org.gradle.tooling.model.ProjectModel. [IDEA-386409]
The IDE now correctly connects to the WildFly admin process after server startup, restoring deployment and the Open browser after launch option. [IDEA-387483]
The IDE no longer fails to locate the WSL 2 JDK. [IJPL-222935]
Double-clicking an Ant target in the Ant tool window now runs the target and shows the build output in the Messages tool window. [IDEA-387507]
Search for context actions and code completion in large Spring projects are now more responsive and faster. [IDEA-378966]
The IDE now correctly supports creating a run configuration for a local WebLogic server. [IDEA-387617]
The Find and Replace action now works as expected when pressing Enter. [IJPL-240373]
To find out more details about the issues resolved, please refer to the release notes.
If you encounter any bugs, please report them to our issue tracker.