
Through many discussions with industry colleagues, we’ve started hearing a phrase more often when swapping stories about AI adoption:
“Now I don’t have to bug [someone].”
Product designers don’t need to bug researchers anymore — retrieval-augment generation (RAG) tools surface insights instantly. Product Managers don’t need to bug designers for mockups — AI generates acceptable options. Engineers don’t need to bug accessibility teams — automated scanners flag issues in real-time.
It’s framed as liberation, and in many ways, it is. There’s genuine relief in being unblocked, in not having to wait, in solving problems independently.
With AI, we’re building a “bug-free workforce”.
But what if the bugs that AI is automating away, such as the quick questions, the small talk, the organic connections, are actually an important part of the scaffolding that builds and sustains healthy teams?
The Vanishing Scaffolding
Consider what actually disappears when we turn to AI assistance before engaging with a colleague directly. For instance:
- The 2-minute Slack exchange that turns into a 20-minute whiteboarding session.
- The “quick question” that reveals a fundamental misalignment.
- The accessibility review that becomes mentorship.
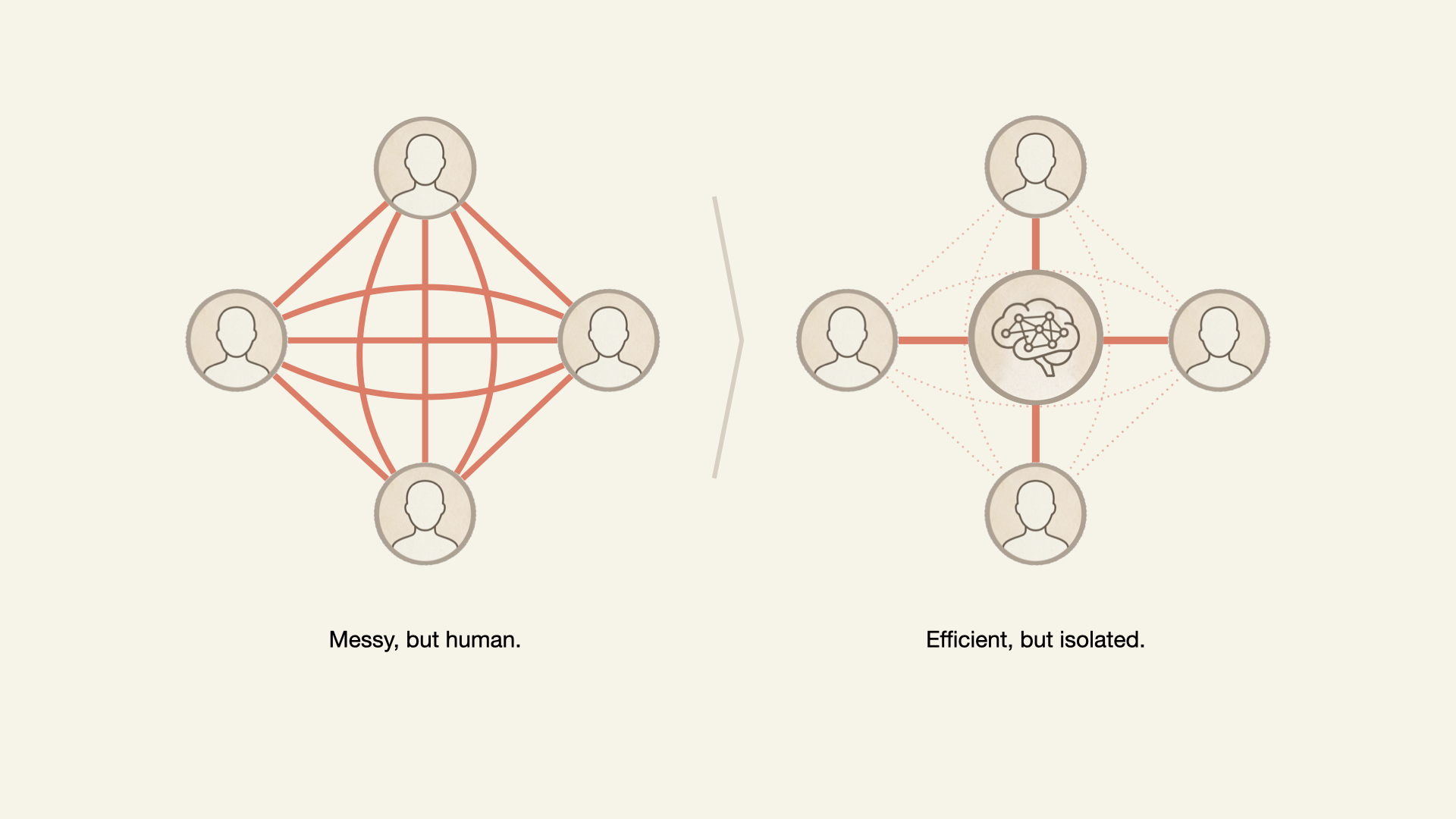
Although these interactions are primarily intended to exchange information and unblock individuals’ tasks, many are the building blocks for the intangible but crucial sense of belonging and connection in the workplace.
The inefficiencies of interpersonal communication and daily interaction build the larger organism known as work culture. When AI disrupts these interactions, what is lost?
What The Research Actually Shows
There is ample psychological research to support our hypothesis: If the trust built through organic and informal connections is threatened, teams will be negatively impacted. Let’s examine a few:
In 2012, MIT’s Human Dynamics Lab (Pentland, 2012) discovered that the best predictor of team productivity wasn’t formal meetings but “energy” from informal communication: the hallway conversations, coffee chats, and quick questions. Teams with the most informal interaction had 35% more successful outcomes. With AI, what energy is not generated, leading to fewer successful outcomes?
In 2015, Google’s Project Aristotle studied over 180 teams to find out why some thrived, and others underperformed. They found that psychological safety, the shared belief among team members that the environment is safe for interpersonal risk-taking, built through frequent, low-stakes interactions, was the number one predictor of high performance. Not intelligence. Not resources. Trust built through micro-moments. The exact micro-moments we see vanishing when we overuse AI.
In 2025, researchers from Harvard, Columbia, and Yeshiva University published a study focused on the impact of AI on performance and team coordination. The authors concluded that AI-driven automation decreased overall team performance and increased coordination failures. These effects were especially large in the short-term and in low- and medium-skilled teams. Automation also decreased team trust.
Why This Matters
When AI disrupts the team’s energy and psychological safety, a sense of disconnection sets in, which, in turn, hurts the company’s bottom line.
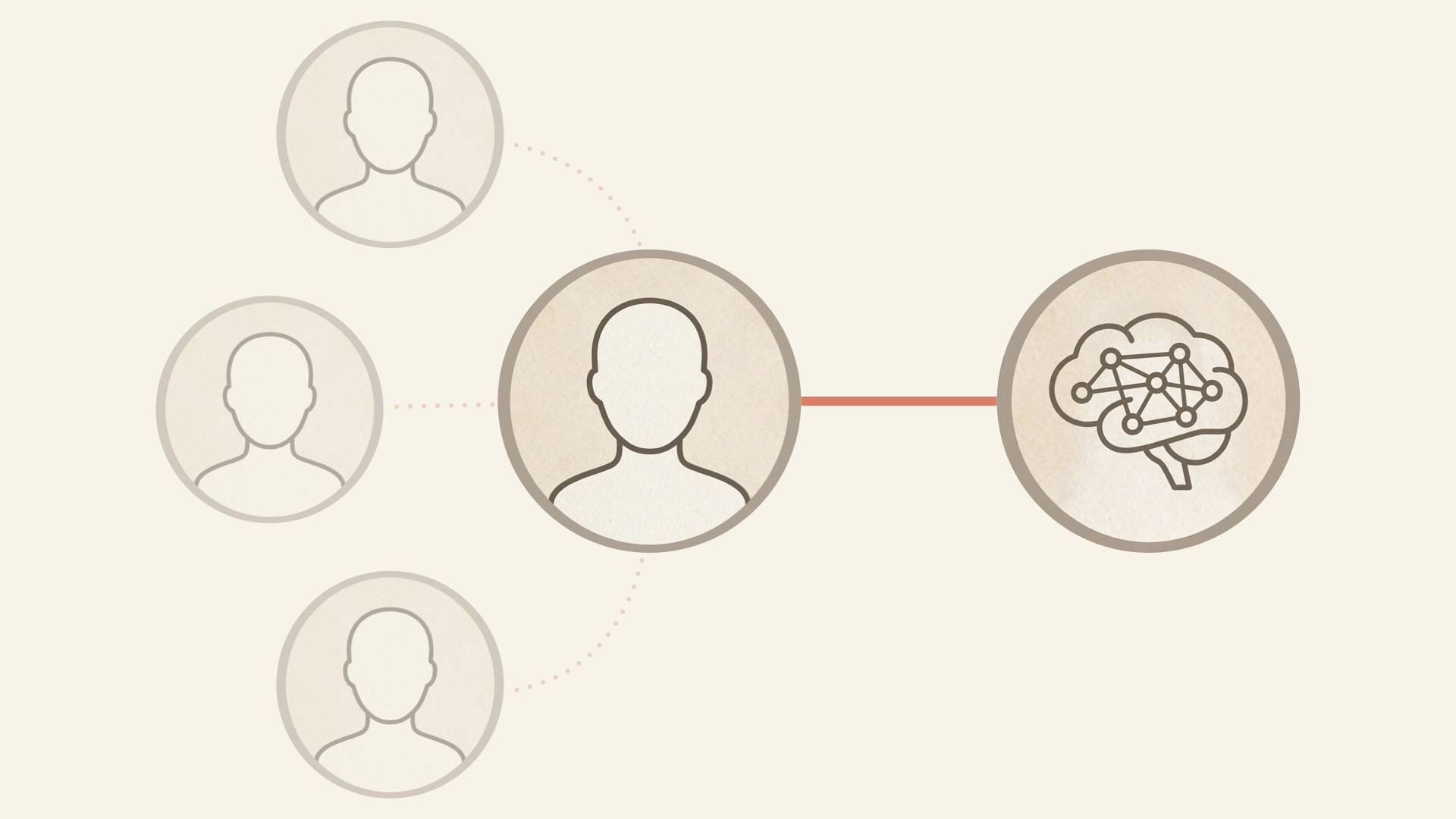
Disconnected Employees Leave
People don’t stay at companies because of the work. They stay because of the people. And if connections to colleagues decrease due to AI’s presence, how might that expedite one’s departure?
Consider this question in dollar terms. McKinsey’s Great Attrition research found that not feeling a sense of belonging was one of the most frequently cited reasons employees left. When informal micro-interactions disappear, belonging erodes, and people walk.
“Employee disengagement and attrition could cost a median-size S&P 500 company between $228 million and $355 million a year in lost productivity.”
— McKinsey
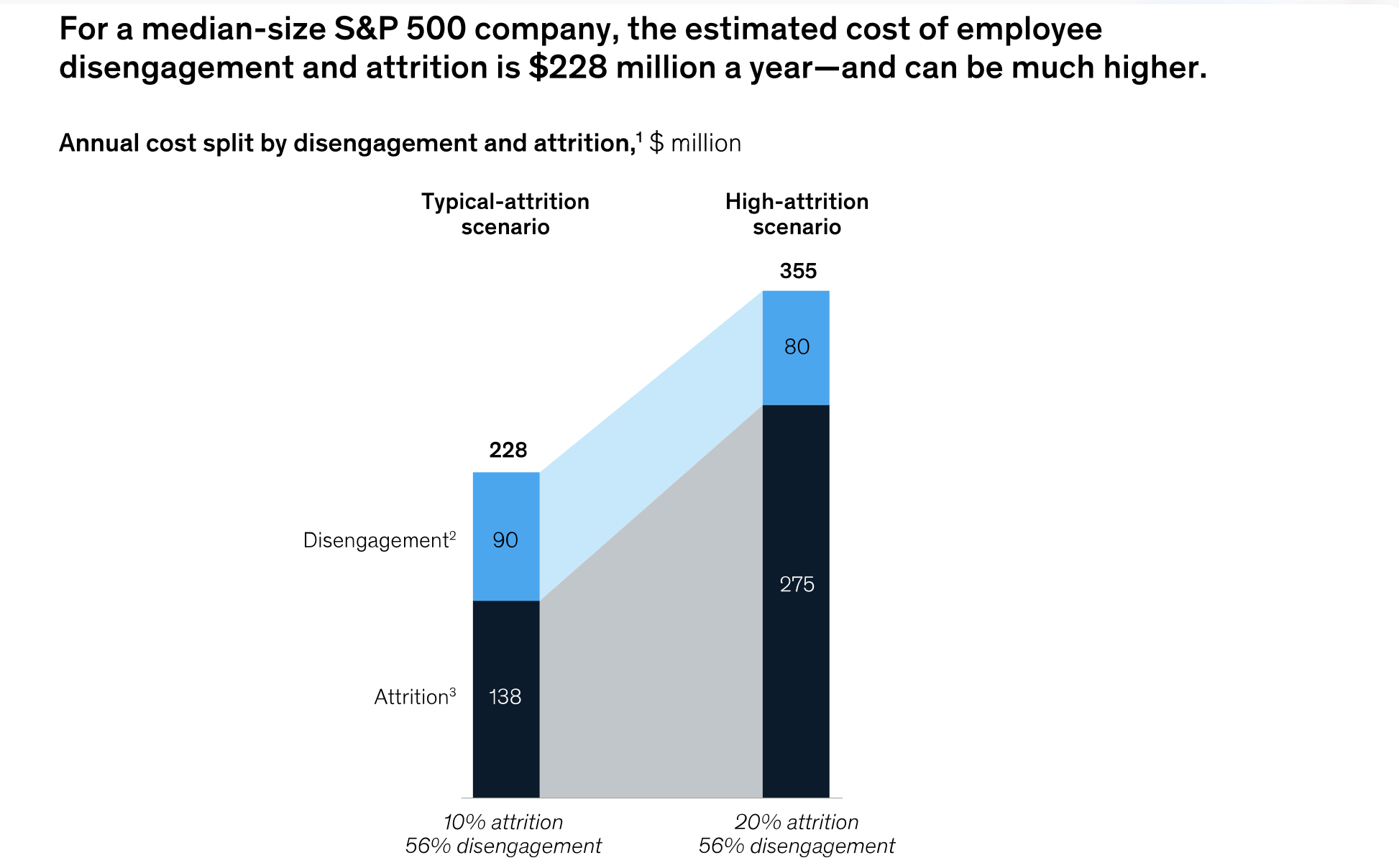
Leaders must ask themselves if the potential gains from AI rollouts and promised productivity gains outweigh the costs of a disengaged and attrition-prone workforce. The evidence suggests otherwise.
Disconnected Teams Are Less Innovative
Korean researchers in 2024 analyzed innovation in the private sector and concluded that weak ties — the bridging conversations with people you interact with occasionally — sustained innovative performance in companies characterized by active technological innovation.
Simply put, breakthroughs do not necessarily emerge from your core team but from interactions with the people you would have “bugged” in the past. Eliminating these interactions in favor of AI could not only negatively impact team health, but it could also hurt the business through decreased depth and breadth of innovation in design, coding, content, and beyond.
AI’s seduction is that it feels like pure gain until the team realizes they’ve become strangers who happen to work on the same project.
If a shared sense of purpose and belonging disappears, employers have a workforce less engaged and less innovative, with a higher chance of attrition.
If AI helps us need each other less, how can a company hope to nurture a connected, supported, and effective workforce?
The answer requires a balanced and multi-pronged approach. Use AI tools for dull, repetitive, and high-volume tasks while reserving the human brain for higher-level problem solving. Design physical workspaces and online team interactions that will maintain or increase human connection.
Maintaining The Best Of Both
In short, leverage the best of AI tools and human abilities.
1. Use AI To Eliminate The Toil
In the March 2026 article “When Using AI Leads to ‘Brain Fry’,” the authors outline their study of 1,488 full-time U.S.-based workers to understand the impact of AI use on professionals. The result was a concept they call “AI Brain Fry,” a form of acute mental fatigue and cognitive exhaustion resulting from excessive use, interaction, or oversight of AI tools beyond an individual’s cognitive capacity.
Further, the study reveals that the cognitive strain created by intensive AI use carries business costs, including decision fatigue and error-prone work. Perhaps the most troubling finding is that 34% of workers who reported experiencing brain fry intended to quit their jobs. The loss of institutional knowledge caused by turnover is well documented.
One conclusion is that AI is not inherently bad or cognitively taxing. Rather, as with any tool, what matters is how it’s used.
Focusing our energy on identifying the repetitive, unenjoyable parts of our jobs (or “toil”) and using AI to remove them is a way to improve cognitive and team health.
Indeed, the Harvard Business Review authors explain that participants in their study who used AI to eliminate toil only had 15% lower rates of burnout but also reported “a higher degree of social connection with peers…because they had more time to spend ‘off keyboard.’” In this toil-elimination scenario, AI did not disrupt team connections; it removed what we consider busy work that prevented the team from solving problems with colleagues.
2. Institutionalize Productive Friction
Steve Jobs famously designed the Pixar studios so employees would have to bump into each other. “Steve realized that when people run into each other, when they make eye contact, things happen,” reflected Brad Bird, the director of The Incredibles and Ratatouille movies. John Lasseter, responsible for some of Pixar’s most beloved films, shared that he’d “never seen a building that promoted collaboration and creativity as well as this one.” Jobs understood that serendipitous collision drives creative work, and Pixar’s oeuvre reveals the genius.

What is the equivalent of creating this type of organizational design in the age of AI?
- Build AI tools that connect the team.
We’ve found that when building internal agents, it’s best to attach the names of the original creators to the work and to direct seekers to these creators. This way, any seeker not only finds the answer but is connected to others with more institutional knowledge to help. - Publicly spotlight successful team uses of AI.
By finding examples of how teams have used AI to work more effectively and efficiently together and highlighting them in public forums and townhalls, it helps establish the narrative that AI can be something that brings us together rather than pushes us apart. - Establish rotation programs.
If AI means product managers can prototype, have them shadow designers anyway. Having a more holistic understanding of each other’s craft through direct dialogues benefits both sides beyond simple AI outputs. - Hold panel discussions on the evolution of work.
Gather cross-functional partners to regularly discuss and debate how our work is currently changing or could in the near future. It keeps intentional change top of mind and in the open.
3. Build Team Cohesion Through AI-inspired Laughter
Positive humor in the workplace has been studied extensively as a way for teams to bond. We see how AI can improve team connections through a good, absurd laugh.
- Bad UX Vibecoding Competitions
Give your team a silly prompt (“Design the worst volume control”) and 30 minutes to vibe-code a horrible solution. The process of building these outputs helps the team: learn new AI tools, get the creative juices flowing, and, most importantly, laugh together.
- Hyper-specific AI Creations
Would a certain image make people smile in this workshop? Is there a funny idea at work that would be even weirder as an AI-generated song? Using them for absurd work moments is a fun way to get people laughing.

Eliminating toil, institutionalizing productive friction, and building team cohesion through humor show the power of integrating the best of the human brain and AI algorithms.
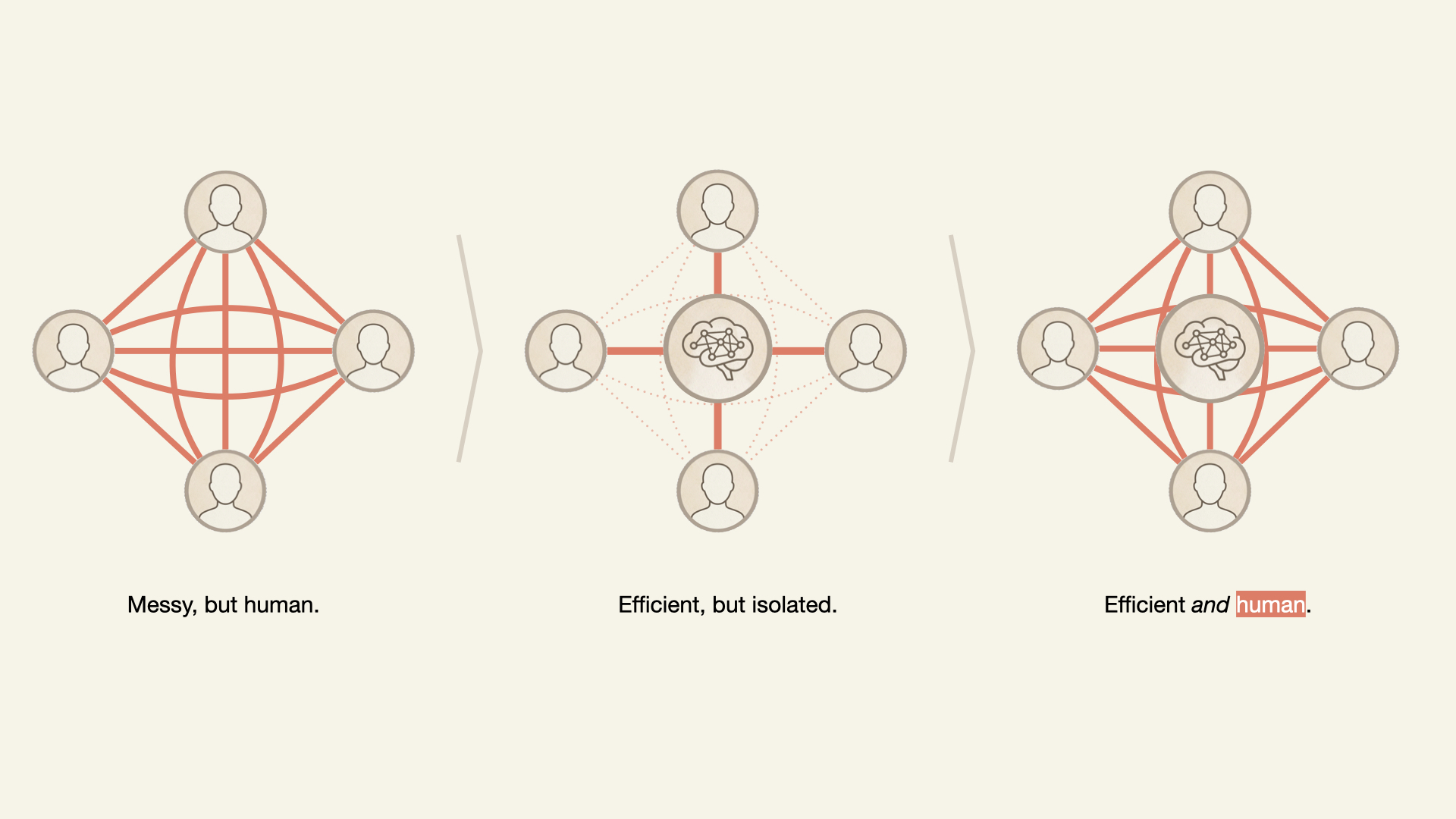
The question isn’t whether to use AI. Contemporary workers have less and less choice. The question is: what kind of team do you want to become when AI is the newest teammate?
Conclusion
Leaders who introduce artificial intelligence with an equal amount of emotional intelligence will enable their teams to thrive by leveraging the power of AI while also shielding their teams from the inherent risks associated with the disruptive natures of these new tools.
When the unexpected hits — the crisis, the pivot, the moment that requires trust you can’t manufacture overnight — it will be the teams with cultures intact that will thrive.
References
- The 4 Stages of Psychological Safety: Defining the Path to Inclusion and Innovation, Clark, T. R. (2020), Berrett-Koehler Publishers
- What Google Learned From Its Quest to Build the Perfect Team, Duhigg, C. (2016), The New York Times Magazine
- Psychological Safety and Learning Behavior in Work Teams, Edmondson, A. C. (1999), Administrative Science Quarterly, 44(2)
- The Strength of a Weak Tie in the Innovative Performance of Firms: A Case of Korean High-tech Manufacturing Small and Medium-sized Enterprises, Hong, Jinki; Lee; Raehyung; Ohm, Jay Y.;, Lee, Duk Hee (2024), Sociology Compass Volume 18, Issue 5
- How Psychological Safety Impacts R&D Project Teams, Liu, Yuwen; Keller, R.T. (2021), Research-Technology Management Volume 64, Issue 2
- Creating Psychological Safety in the Workplace, McCausland, Tammy (2023), Research-Technology Management Volume 66, Issue 2
- Some Employees Are Destroying Value. Others Are Building It. Do You Know the Difference?, De Smet, Aaron; Mugayar-Baldocchi, Marino; Reich, Angelika; Schaninger, Bill (September 11, 2023), McKinsey Quarterly
- The New Science of Building Great Teams, Pentland, A. (2012), Harvard Business Review
- Super Mario Meets AI: Experimental Effects of Automation and Skills on Team Performance and Coordination, Dell’Acqua, Fabrizio; Kogut, Bruce; Perkowski, Patryk (2025), The Review of Economics and Statistics 107 (4)
- Humor Is Serious Business: Why Humor Is A Secret Weapon In Business And Life, Aaker, J; Bagdonas, Naomi (2021)


