
Dealing with bugs is a natural part of software development. But it can also be among the most costly, especially when they don’t get discovered until later in the development lifecycle. The daunting part is that many bugs aren’t immediately obvious.
Issues like memory leaks, default credentials, and hardcoded tokens are easily missed in manual code reviews, going relatively unnoticed until they cause problems late in development or post-launch. This can spike the cost of development through security vulnerabilities, downtime, reputational damage, and unwanted spending on rework.
That’s where static code analysis comes into play. It changes the way you approach code defects by shifting detection earlier in the process, prioritizing fixes without running code, and minimizing the impact and cost of bugs by making changes quicker and easier.
Let’s take a closer look at the costs associated with software bugs and explore how static code analysis helps save you money on related fixes.
Table of Contents
The true cost of software bugs
Every undetected bug comes with a price. But the scale might come as a surprise. According to a report by the Consortium for Information & Software Quality (CISQ), poor software quality cost the US economy $2.41 trillion in 2022. That includes everything from application downtime and debugging to productivity drains.
In addition, IBM’s Cost of a Data Breach Report 2025 reports that the estimated average global cost of a data breach is $4.44 million, with many breaches traced back to software bugs.
Get A Cost-Saving Demo
How the cost grows with time
The cost of software bugs isn’t static. It escalates through the development, testing, and production stages. Essentially, the later in the process a bug is identified, the more it costs.
A 2010 study from the IBM System Sciences Institute shows the value of early bug identification. It said a bug identified at the traditional testing stage can cost 15 times more to fix than one found during design. And this only climbs higher when bugs sneak through to maintenance, costing up to 100 times more.
The average cost of a bug quickly adds up, including:
- Downtime and production outages, leading to revenue loss and expensive hotfixes to get back online.
- Rework, which is more time-consuming and complex if bugs are discovered later in the process, when developers don’t have a fresh view of the code. If a bug is discovered during coding, the developer immediately knows why they wrote it that way and the decisions they took, so they can easily unpick it. When it’s discovered later, whoever is tasked with removing the bug needs to take time to understand what the original developer did and why before they can fix the problem.
- Context switching, when developers constantly need to shift tasks, leading to increased errors and more time and money spent on fixes.
- Security breaches and non-compliance, which can cost almost three times as much as compliance, thanks to fines and reputational damage.
- Technical debt through wasted developer time that could be spent reducing existing maintenance needs.
How static code analysis reduces bug costs
Static code analysis transforms how you handle code quality. Applying a shift-left mindset brings crucial tasks like testing and code quality to the front of the timeline, reducing the cost of required fixes in several ways.
Early detection, easier fixes
Earlier detection means changes are actioned at the cheapest point, before bugs reach QA or production. Faster feedback loops also let your developers rework code while the context is fresh. No unpicking or trying to understand someone else’s thinking later in the process means bugs can be fixed instantly, rather than taking days.
Lower production risks
Undetected bugs can wreak havoc in a live environment. Static code analysis flags security issues and vulnerabilities before merge. So you can avoid incidents, rollbacks, potential financial penalties, reputational damage, and the added cost of emergency developer resources.
Freeing up your team
Static code analysis frees your team up and unblocks backlogs. Automating repeatable checks reduces the burden of manual code review and debugging, allowing your team to focus on more complex issues, coding, and improving development efficiency and costs.
Repaying your technical debt
Enforcing code quality standards keeps codebases maintainable and reasonably inexpensive to run. That lets you focus on reducing your technical debt, rather than watching it further stack up and adding mental load.
Static code analysis in CI/CD pipelines
Static code analysis maximizes its cost-saving powers when deployed as part of the CI/CD (continuous integration and continuous delivery/development) pipeline. As your driver of code quality, it doesn’t just help you spot bugs, it stops them from ever reaching your codebase.
When you run static code analysis on every commit, you automatically check for issues as part of your standard development lifecycle. By checking code quality and security vulnerabilities, including those highlighted by security coding standards like OWASP, you ensure errors are spotted and fixed before code is merged into the main branch.
Failed quality gates in your CI/CD pipeline stop progress when the code doesn’t meet the required standard. Your developers must fix these and rerun the full or partial CI pipeline before progressing, meaning identifiable bugs simply never reach your codebase.
This significantly reduces costs in the long term by removing the ability to bypass failed quality gates, which can lead to increased technical debt, security problems, and production bugs.
How Qodana helps your teams control bug costs
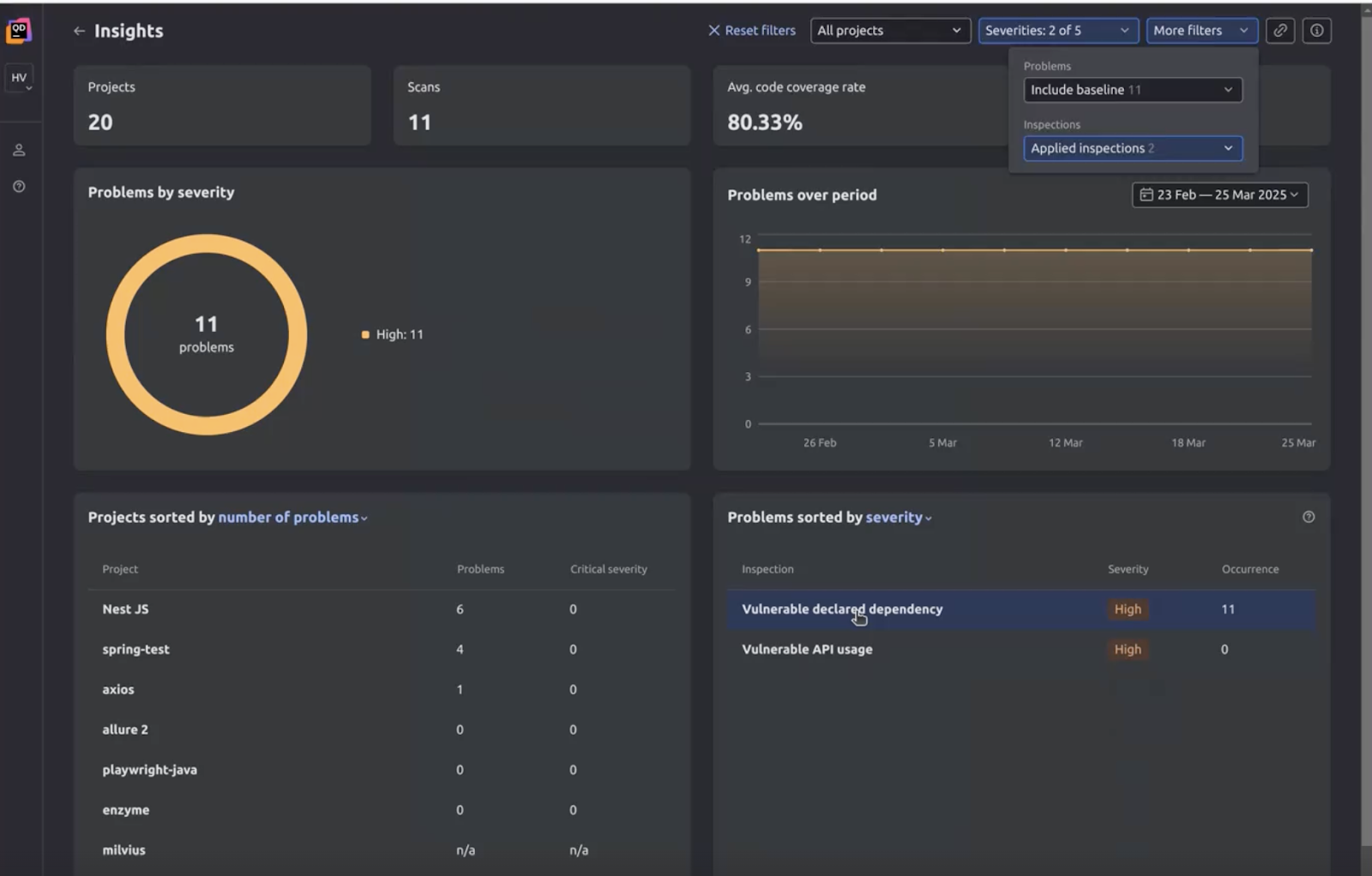
Qodana reinvents your code quality processes. It lets your development team identify issues and fix them earlier through real-time feedback, consistent code standards, and suggested fixes.
That means you deliver secure, high-quality code without incurring the costs of refactoring and downtime. And all within the environments your team is already working in, for smooth integration.
The Qodana code quality tool is built on and uses the linters of JetBrains IDEs, trusted by more than 18 million developers since 2001, and integrates with tools developers already use. It drives code quality and reduces debugging costs through:
- Ready-to-use pipelines for popular CI systems such as Azure Pipelines, CircleCI, Jenkins, GitHub Actions, GitLab CI/CD, and more.
- Consistent rules and code quality checks across local development, IDE, and CI.
- Quality gates that stop risky code before merge, minimizing potential future technical debt.
- Clear and actionable reports that suggest automatic fixes and reduce repair time and associated costs.
Scenario: How to find and reduce bug costs in testing
How does static code analysis reduce costs in practice? Let’s say your team is working on a project to improve the design of your product and add new features. However, a code or configuration change unintentionally causes a security weakness by hardcoding secret values that have embedded API keys.
The result is that these values could be exposed to anyone with access to the codebase, including version control history. If the bug goes undetected, your systems will be vulnerable to unauthorized access and data breaches, resulting in downtime, reputational damage, and more time, resources, and money spent on fixes.
This can also be caused by code changes that weaken security by:
- Logging sensitive data, such as credentials, leading to security and compliance risks.
- Using insecure cryptographic APIs or misusing secure ones.
- Missing authentication checks that may result in information exposure.
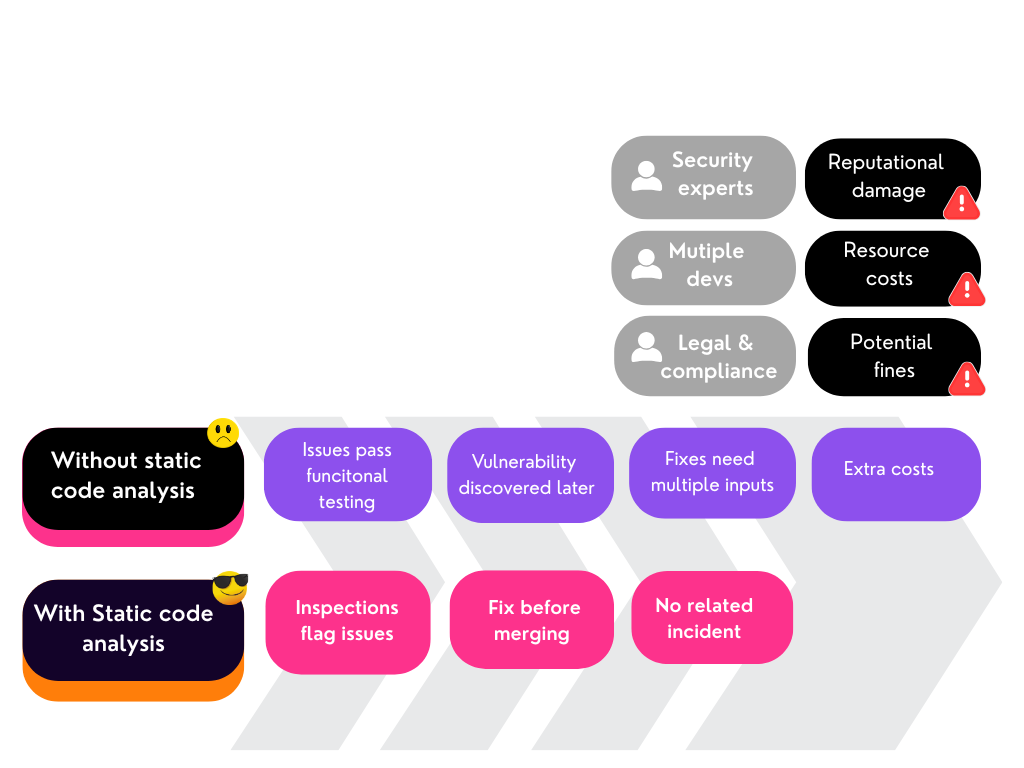
Without static code analysis
Without static code analysis, this vulnerability could easily make it through manual code review. Because it’s not obvious, it might pass functional testing and not be uncovered until close to or after release, during a security audit, or penetration test.
Worse still, if the issue makes it into your shipped product, it can even be found and exploited by an attacker, costing far more than just the resource needed for debugging.
Fixing the problem in a live environment can require coordinated patches and quick fixes, which may cost much more than if the error was detected and rectified during development. It can also lead to:
- Additional resource costs for personnel and security reviews to fix the issue.
- Large fines by regulatory bodies, such as the SEC (Securities and Exchange Commission) and FTC (Federal Trade Commission).
- Delayed certifications, which may lead to financial, operational, and legal penalties.
- Reputational damage and the associated costs of lost business.
With static code analysis
Static code analysis significantly reduces the cost of dealing with such a vulnerability. At commit or pull request, the vulnerability is flagged and progress stopped. The developer working on that code is automatically alerted and required to fix the issue before merging code. This stops the bug in its tracks and prevents it from becoming part of your wider codebase, meaning there’s a quicker fix and no fallout.
The process ensures security is a proactive priority, rather than a reactive expense. It helps mitigate vulnerabilities causing security problems during testing and execution. It also reduces the risk and high costs of compliance breaches.
Reduce software bugs and costs with Qodana
Static code analysis is an important part of lowering the cost of software bugs and fixes. Identify problems before they escalate into expensive issues.
Try Qodana for free with a 60-day trial for your project.
Speak To Qodana





