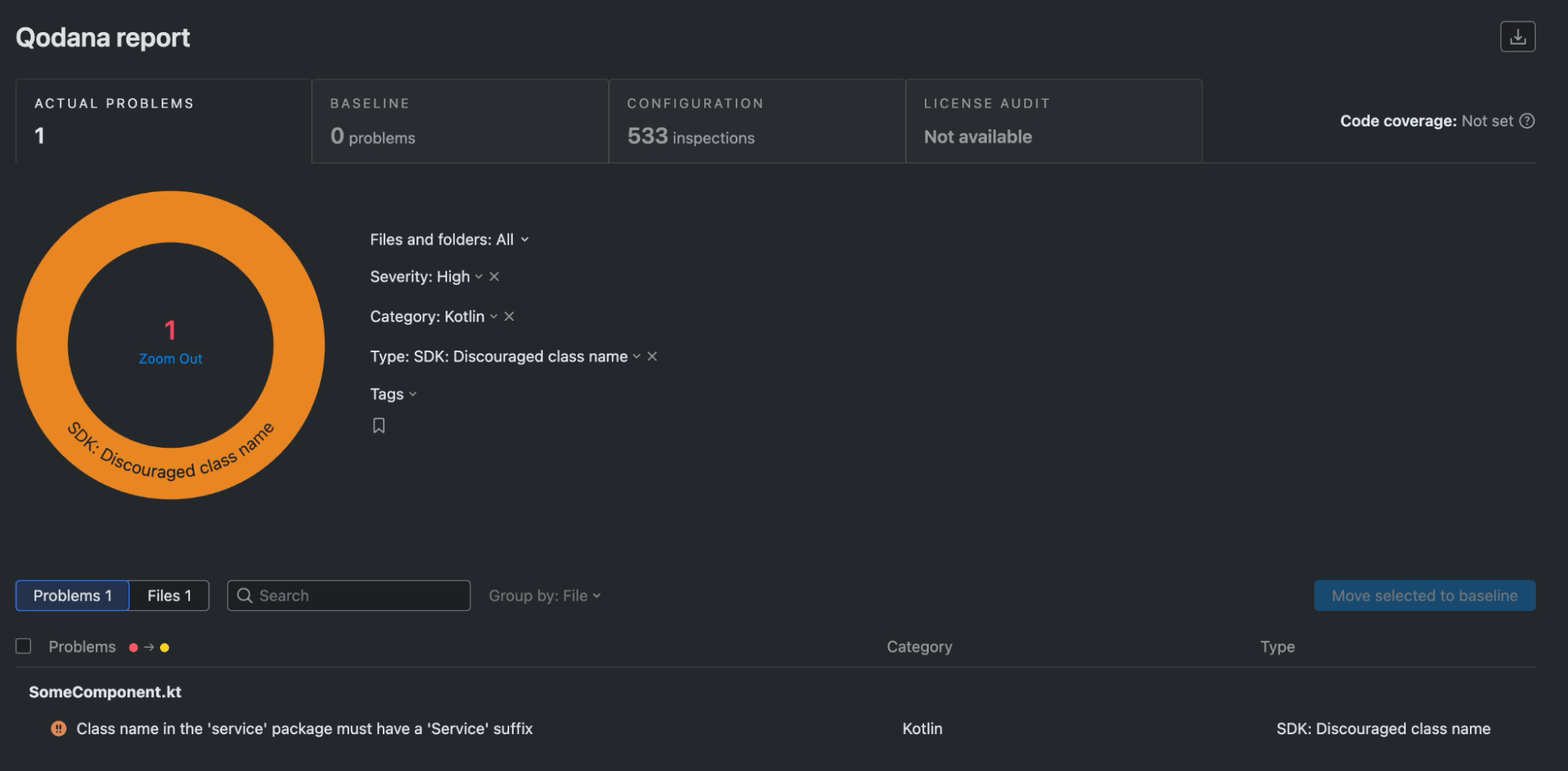
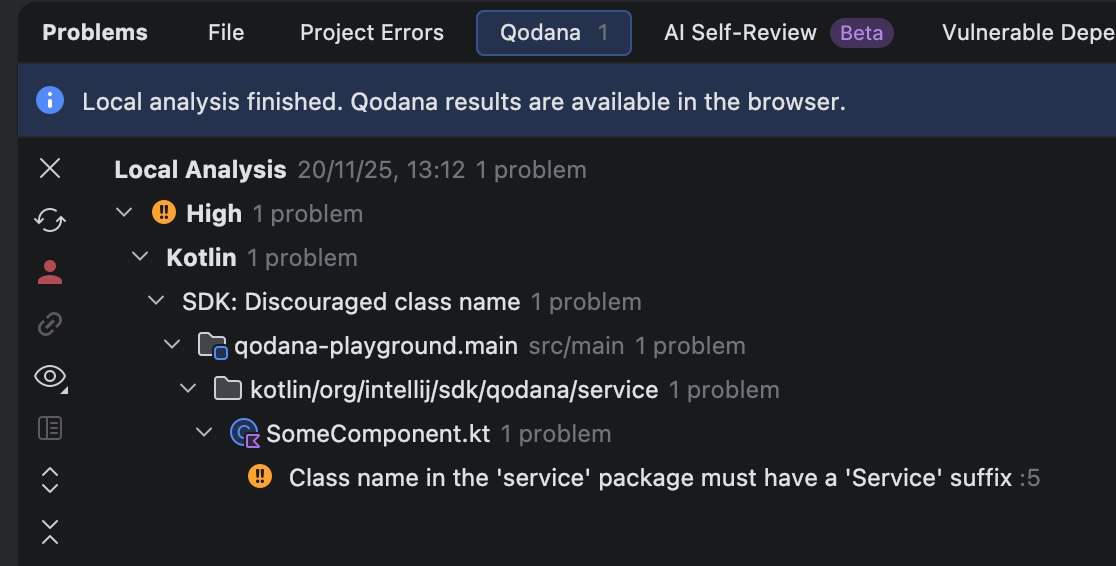
When learning the principles of basic CSS, one is taught to write modular, reusable, and descriptive styles to ensure maintainability. But when developers become involved with real-world applications, it often feels impossible to add UI features without styles leaking into unintended areas.
This issue often snowballs into a self-fulfilling loop; styles that are theoretically scoped to one element or class start showing up where they don’t belong. This forces the developer to create even more specific selectors to override the leaked styles, which then accidentally override global styles, and so on.
Rigid class name conventions, such as BEM, are one theoretical solution to this issue. The BEM (Block, Element, Modifier) methodology is a systematic way of naming CSS classes to ensure reusability and structure within CSS files. Naming conventions like this can reduce cognitive load by leveraging domain language to describe elements and their state, and if implemented correctly, can make styles for large applications easier to maintain.
In the real world, however, it doesn’t always work out like that. Priorities can change, and with change, implementation becomes inconsistent. Small changes to the HTML structure can require many CSS class name revisions. With highly interactive front-end applications, class names following the BEM pattern can become long and unwieldy (e.g., app-user-overview__status--is-authenticating), and not fully adhering to the naming rules breaks the system’s structure, thereby negating its benefits.
Given these challenges, it’s no wonder that developers have turned to frameworks, Tailwind being the most popular CSS framework. Rather than trying to fight what seems like an unwinnable specificity war between styles, it is easier to give up on the CSS Cascade and use tools that guarantee complete isolation.
Developers Lean More On Utilities
How do we know that some developers are keen on avoiding cascaded styles? It’s the rise of “modern” front-end tooling — like CSS-in-JS frameworks — designed specifically for that purpose. Working with isolated styles that are tightly scoped to specific components can seem like a breath of fresh air. It removes the need to name things — still one of the most hated and time-consuming front-end tasks — and allows developers to be productive without fully understanding or leveraging the benefits of CSS inheritance.
But ditching the CSS Cascade comes with its own problems. For instance, composing styles in JavaScript requires heavy build configurations and often leads to styles awkwardly intermingling with component markup or HTML. Instead of carefully considered naming conventions, we allow build tools to autogenerate selectors and identifiers for us (e.g., .jsx-3130221066), requiring developers to keep up with yet another pseudo-language in and of itself. (As if the cognitive load of understanding what all your component’s useEffects do weren’t already enough!)
Further abstracting the job of naming classes to tooling means that basic debugging is often constrained to specific application versions compiled for development, rather than leveraging native browser features that support live debugging, such as Developer Tools.
It’s almost like we need to develop tools to debug the tools we’re using to abstract what the web already provides — all for the sake of running away from the “pain” of writing standard CSS.
Luckily, modern CSS features not only make writing standard CSS more flexible but also give developers like us a great deal more power to manage the cascade and make it work for us. CSS Cascade Layers are a great example, but there’s another feature that gets a surprising lack of attention — although that is changing now that it has recently become Baseline compatible.
The CSS @scope At-Rule
I consider the CSS @scope at-rule to be a potential cure for the sort of style-leak-induced anxiety we’ve covered, one that does not force us to compromise native web advantages for abstractions and extra build tooling.
“The @scope CSS at-rule enables you to select elements in specific DOM subtrees, targeting elements precisely without writing overly-specific selectors that are hard to override, and without coupling your selectors too tightly to the DOM structure.”
— MDN
In other words, we can work with isolated styles in specific instances without sacrificing inheritance, cascading, or even the basic separation of concerns that has been a long-running guiding principle of front-end development.
Plus, it has excellent browser coverage. In fact, Firefox 146 added support for @scope in December, making it Baseline compatible for the first time. Here is a simple comparison between a button using the BEM pattern versus the @scope rule:
<!-- BEM -->
<button class="button button--primary">
<span class="button__text">Click me</span>
<span class="button__icon">→</span>
</button>
<style>
.button .button__text { /* button text styles */ }
.button .button__icon { /* button icon styles */ }
.button--primary { primary button styles */ }
</style>
<!-- @scope -->
<button class="primary-button">
<span>Click me</span>
<span>→</span>
</button>
<style>
@scope (.primary-button) {
span:first-child { /* button text styles */ }
span:last-child { /* button icon styles */ }
}
</style>
The @scope rule allows for precision with less complexity. The developer no longer needs to create boundaries using class names, which, in turn, allows them to write selectors based on native HTML elements, thereby eliminating the need for prescriptive CSS class name patterns. By simply removing the need for class name management, @scope can alleviate the fear associated with CSS in large projects.
Basic Usage
To get started, add the @scope rule to your CSS and insert a root selector to which styles will be scoped:
@scope (<selector>) {
/* Styles scoped to the <selector> */
}
So, for example, if we were to scope styles to a <nav> element, it may look something like this:
@scope (nav) {
a { /* Link styles within nav scope */ }
a:active { /* Active link styles */ }
a:active::before { /* Active link with pseudo-element for extra styling */ }
@media (max-width: 768px) {
a { /* Responsive adjustments */ }
}
}
This, on its own, is not a groundbreaking feature. However, a second argument can be added to the scope to create a lower boundary, effectively defining the scope’s start and end points.
/* Any a element inside ul will not have the styles applied */
@scope (nav) to (ul) {
a {
font-size: 14px;
}
}
This practice is called donut scoping, and there are several approaches one could use, including a series of similar, highly specific selectors coupled tightly to the DOM structure, a :not pseudo-selector, or assigning specific class names to <a> elements within the <nav> to handle the differing CSS.
Regardless of those other approaches, the @scope method is much more concise. More importantly, it prevents the risk of broken styles if classnames change or are misused or if the HTML structure were to be modified. Now that @scope is Baseline compatible, we no longer need workarounds!
We can take this idea further with multiple end boundaries to create a “style figure eight”:
/* Any <a> or <p> element inside <aside> or <nav> will not have the styles applied */
@scope (main) to (aside, nav) {
a {
font-size: 14px;
}
p {
line-height: 16px;
color: darkgrey;
}
}
Compare that to a version handled without the @scope rule, where the developer has to “reset” styles to their defaults:
main a {
font-size: 14px;
}
main p {
line-height: 16px;
color: darkgrey;
}
main aside a,
main nav a {
font-size: inherit; /* or whatever the default should be */
}
main aside p,
main nav p {
line-height: inherit; /* or whatever the default should be */
color: inherit; /* or a specific color */
}
Check out the following example. Do you notice how simple it is to target some nested selectors while exempting others?
See the Pen @scope example [forked] by Blake Lundquist.
Consider a scenario where unique styles need to be applied to slotted content within web components. When slotting content into a web component, that content becomes part of the Shadow DOM, but still inherits styles from the parent document. The developer might want to implement different styles depending on which web component the content is slotted into:
<!-- Same <user-card> content, different contexts -->
<product-showcase>
<user-card slot="reviewer">
<img src="avatar.jpg" slot="avatar">
<span slot="name">Jane Doe</span>
</user-card>
</product-showcase>
<team-roster>
<user-card slot="member">
<img src="avatar.jpg" slot="avatar">
<span slot="name">Jane Doe</span>
</user-card>
</team-roster>
In this example, the developer might want the <user-card> to have distinct styles only if it is rendered inside <team-roster>:
@scope (team-roster) {
user-card {
display: inline-flex;
align-items: center;
gap: 0.5rem;
}
user-card img {
border-radius: 50%;
width: 40px;
height: 40px;
}
}
More Benefits
There are additional ways that @scope can remove the need for class management without resorting to utilities or JavaScript-generated class names. For example, @scope opens up the possibility to easily target descendants of any selector, not just class names:
/* Only div elements with a direct child button are included in the root scope */
@scope (div:has(> button)) {
p {
font-size: 14px;
}
}
And they can be nested, creating scopes within scopes:
@scope (main) {
p {
font-size: 16px;
color: black;
}
@scope (section) {
p {
font-size: 14px;
color: blue;
}
@scope (.highlight) {
p {
background-color: yellow;
font-weight: bold;
}
}
}
}
Plus, the root scope can be easily referenced within the @scope rule:
/* Applies to elements inside direct child section elements of main, but stops at any direct aside that is a direct chiled of those sections */
@scope (main > section) to (:scope > aside) {
p {
background-color: lightblue;
color: blue;
}
/* Applies to ul elements that are immediate siblings of root scope */
:scope + ul {
list-style: none;
}
}
The @scope at-rule also introduces a new proximity dimension to CSS specificity resolution. In traditional CSS, when two selectors match the same element, the selector with the higher specificity wins. With @scope, when two elements have equal specificity, the one whose scope root is closer to the matched element wins. This eliminates the need to override parent styles by manually increasing an element’s specificity, since inner components naturally supersede outer element styles.
<style>
@scope (.container) {
.title { color: green; }
}
<!-- The <h2> is closer to .container than to .sidebar so "color: green" wins. -->
@scope (.sidebar) {
.title { color: red; }
}
</style>
<div class="sidebar">
<div class="container">
<h2 class="title">Hello</h2>
</div>
</div>
Conclusion
Utility-first CSS frameworks, such as Tailwind, work well for prototyping and smaller projects. Their benefits quickly diminish, however, when used in larger projects involving more than a couple of developers.
Front-end development has become increasingly overcomplicated in the last few years, and CSS is no exception. While the @scope rule isn’t a cure-all, it can reduce the need for complex tooling. When used in place of, or alongside strategic class naming, @scope can make it easier and more fun to write maintainable CSS.
Further Reading
- CSS
@scope (MDN)
- “CSS
@scope”, Juan Diego Rodríguez (CSS-Tricks)
- Firefox 146 Release Notes (Firefox)
- Browser Support (CanIUse)
- Popular CSS Frameworks (State of CSS 2024)
- “The “C” in CSS: Cascade”, Thomas Yip (CSS-Tricks)
- BEM Introduction (Get BEM)