Anthropic Self-Hosted Sandboxes + MCP Tunnels: Enterprise AI Agents That Keep Your Data Behind Your Walls
TL;DR Summary
- Anthropic now supports self-hosted sandboxes — agent orchestration stays on Anthropic’s side, but code execution runs on your own servers (Cloudflare, Vercel, Modal, or on-prem)
-
MCP tunnels provide encrypted access to private databases and internal APIs through a single outbound connection — no inbound firewall holes, no public endpoints
-
Mid-session tool swapping lets you change tools and MCP servers without restarting the agent session
-
100K+ token MCP outputs auto-offload to sandbox files instead of bloating the agent’s context window
- Powered by OS-level sandboxing (Seatbelt on macOS, bubblewrap on Linux) with layered filesystem and network isolation
Direct Answer Block
Anthropic’s enterprise infrastructure upgrade separates agent reasoning (which stays on Anthropic’s cloud) from code execution (which moves to your infrastructure). Self-hosted sandboxes keep sensitive files behind your firewall. MCP tunnels connect Claude to private databases and APIs through one encrypted outbound connection with zero inbound firewall rules. Mid-session tool swapping eliminates restarts, and large output offloading prevents context bloat.
Introduction
The enterprise AI adoption conversation has shifted from “can it do the work?” to “where does the work happen?” For regulated industries — finance, healthcare, defense — the answer can’t be “on a vendor’s cloud.” Anthropic’s latest infrastructure moves address this directly: self-hosted sandboxes that execute code on your servers, MCP tunnels that reach private services without exposing them, and quality-of-life improvements like mid-session tool swapping. The age of “just trust our cloud” is yielding to “keep everything behind your own walls.”
How do self-hosted sandboxes split agent orchestration from code execution — and why does this matter for enterprise data residency?

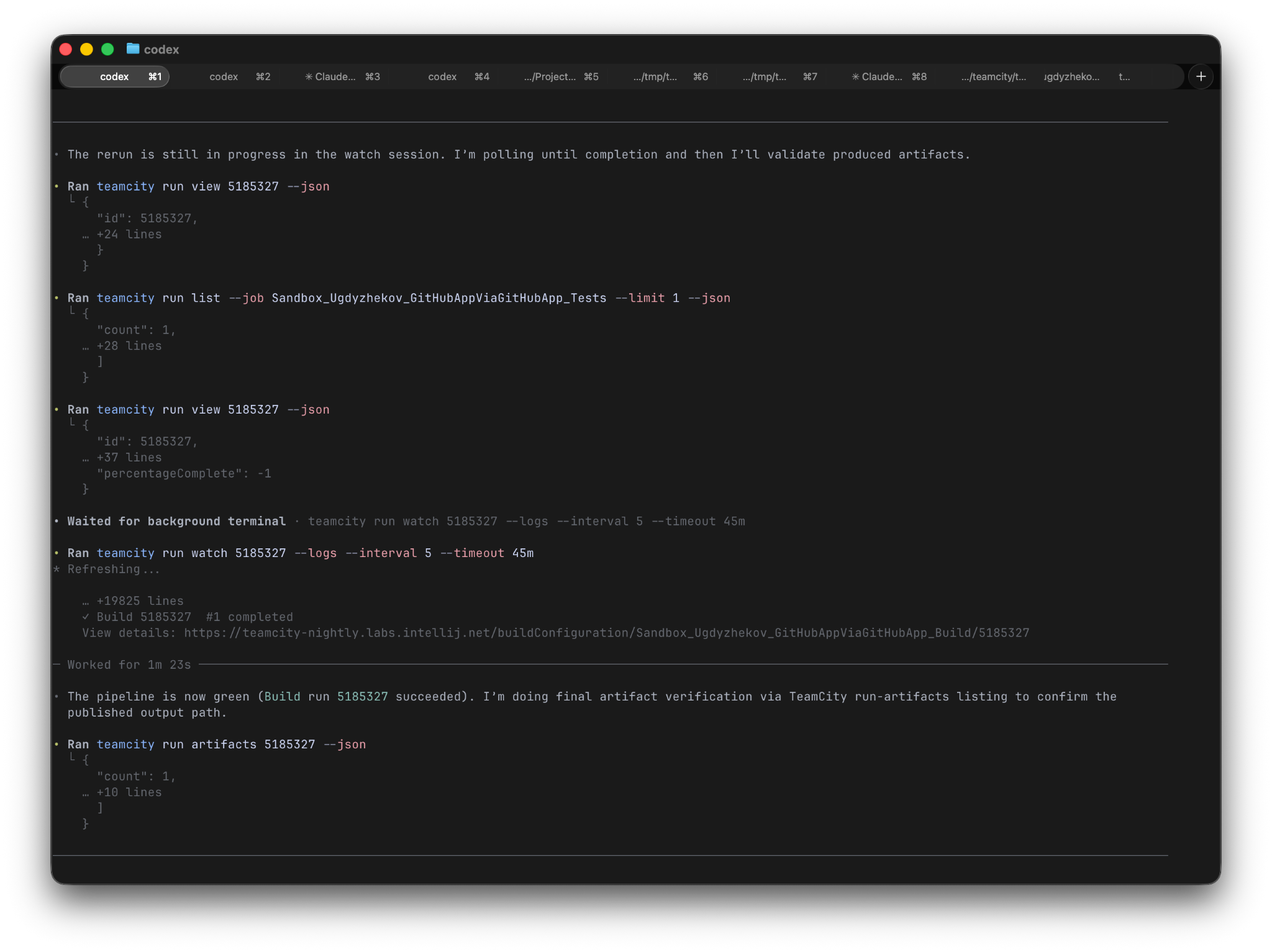
The architectural split is the core innovation. According to the AlphaSignal newsletter: “Agent orchestration stays on Anthropic’s side, but tool execution moves to your infrastructure. Files never leave your perimeter.”
This means Claude’s reasoning — the model thinking, the decision-making, the prompt processing — happens on Anthropic’s infrastructure. But when the agent needs to execute code (read a file, run a shell command, install a package, generate output), that execution happens inside a sandbox running on your servers.
The sandbox can run on managed providers (Cloudflare, Vercel, Daytona, Modal) or on your own on-prem infrastructure. The key property: your files never leave your network. Source code, proprietary data, environment variables, API keys — everything the agent touches during execution stays behind your firewall.
Anthropic’s existing OS-level sandboxing architecture (Seatbelt on macOS, bubblewrap on Linux) provides the enforcement layer. According to Anthropic’s sandboxing documentation: “The sandboxed bash tool uses OS-level primitives to enforce both filesystem and network isolation.” The self-hosted sandbox extends this architecture — instead of the sandbox running on Anthropic’s machines, it runs on yours, with the same OS-level enforcement guarantees.
For enterprises with data residency requirements (GDPR, HIPAA, SOC 2, FedRAMP), this architectural split means the agent can process sensitive data without that data ever touching third-party infrastructure during code execution. The model’s thinking is still on Anthropic’s cloud, but the thinking doesn’t contain the raw data — it contains prompts and tool call instructions.
How do MCP tunnels let Claude access private databases and internal APIs through a single outbound connection?
MCP (Model Context Protocol) tunnels solve the enterprise network access problem. The traditional approach to letting an external service access your internal APIs involves: opening firewall ports, configuring VPNs, setting up public endpoints, managing certificates. Each step is a security review. Each endpoint is an attack surface.
MCP tunnels reverse the connection: the tunnel is initiated from inside your network, as a single outbound connection to Claude Code. No inbound firewall rules. No public endpoints. No exposed services.
The AlphaSignal newsletter describes the mechanism: “MCP tunnels let agents talk to internal databases and APIs through a single outbound encrypted connection — no inbound firewall rules, no public endpoints.”
Traffic is encrypted end-to-end. The tunnel carries MCP tool calls — Claude accessing your private Postgres database, your internal ticketing system, your proprietary API — as if the agent were running inside your network. But the only network change is one outbound connection.
This pattern is similar to how Cloudflare Tunnels and ngrok work: the client inside the network establishes an outbound connection to the service, and traffic flows through that tunnel. No ports are opened. No DNS records are changed. The connection is initiated from the trusted side.
The newsletter notes that the tunnel configuration can be changed mid-session — you don’t need to restart the agent to connect to a different database or API. This is part of the broader “mid-session tool swapping” capability.
How does mid-session tool and MCP server swapping eliminate restarts in long-running agent sessions?
One of the frustrations of long-running agent sessions: you start a session, realize you need a tool that wasn’t configured, and have to restart. Every restart loses context. Every restart costs time.
Anthropic’s update allows mid-session tool and MCP server changes. According to the newsletter: “Swap tools and MCP servers mid-session without restarting.” This means:
-
Add tools during an active session: if the agent discovers it needs a database connector halfway through a task, you can add it without stopping
-
Switch MCP server configurations: change which backend the agent connects to (e.g., switch from staging to production database)
-
Remove unused tools: reduce context bloat by dropping tools the agent no longer needs
-
Update tool configurations: change API endpoints, authentication tokens, or tool parameters mid-task
This is particularly valuable for complex multi-step tasks where the agent’s tool requirements evolve. A security audit might start with code analysis tools, then need database access when it finds a potential SQL injection, then need Slack access to notify the team — all in the same session.
How does offloading 100K+ token MCP outputs to sandbox files prevent context bloat and improve session length?
Large MCP tool outputs are a context problem. When an agent queries a database and gets back 100,000 tokens of results, those tokens consume the context window — the agent has less room for reasoning, instruction following, and conversation history. Long sessions degrade as context fills with tool output rather than productive content.
The solution: auto-offload large outputs to sandbox files. According to the newsletter: “Large MCP outputs (>100K tokens) auto-offload to sandbox files instead of bloating context.”
The mechanism:
- Agent makes an MCP tool call (e.g., “query all customer records from last quarter”)
- The tool returns a large result set
- Instead of inserting the raw output into the agent’s context, the system writes it to a file in the sandbox
- The agent reads from the file when it needs specific data (using file search, grep, or chunked reads)
- The context stays lean — the agent has a reference to the data without the data consuming its working memory
This is similar to how human engineers work: you don’t load an entire database dump into your brain. You query it, get a reference to the results, and inspect subsets as needed. The sandbox file acts as the agent’s external memory for large data.
For long-running enterprise sessions that might process multiple large data sources, this feature extends the effective session length significantly. A session that would hit context limits after 20 minutes might run for hours, referencing large data files as needed without context exhaustion.
How does the OS-level sandbox (Seatbelt/bubblewrap) layer with self-hosted execution for defense-in-depth?

Anthropic’s sandboxing architecture provides defense-in-depth through layered isolation:
-
Filesystem isolation: The sandbox restricts read and write access to specific directories using OS-level primitives (Seatbelt on macOS, bubblewrap on Linux). According to Anthropic’s documentation: “These restrictions are enforced at the OS level, so they apply to all subprocess commands, including tools like kubectl, terraform, and npm.”
-
Network isolation: A proxy server running outside the sandbox controls domain access. Only approved domains are reachable. New domain requests trigger permission prompts.
-
Self-hosted boundary: With self-hosted sandboxes, an additional boundary — your network perimeter — sits between the agent and sensitive data. Even if the sandbox’s OS-level isolation were compromised, the data is still behind your firewall.
Anthropic’s sandboxing documentation emphasizes: “Effective sandboxing requires both filesystem and network isolation. Without network isolation, a compromised agent could exfiltrate sensitive files like SSH keys. Without filesystem isolation, a compromised agent could backdoor system resources to gain network access.”
The self-hosted sandbox adds a third layer: physical/organizational separation. The sandbox runs on infrastructure you control, under your monitoring, with your access controls. This matters for compliance frameworks that require demonstrated control over data processing locations.
How does Anthropic’s enterprise infrastructure compare to OpenAI Codex and Cursor Cloud on data control?
The competitive landscape on enterprise data control:
| Feature |
Anthropic (2026) |
OpenAI Codex |
Cursor Cloud |
| Code execution location |
Self-hosted (your infra) or Anthropic cloud |
Codex cloud sandbox or local |
Cursor cloud or local IDE |
| Private service access |
MCP tunnels (outbound only, encrypted) |
MCP connectors via API |
IDE-local tools |
| Mid-session tool changes |
Yes |
Limited |
IDE-native (local) |
| Context offloading |
100K+ token auto-offload |
Compaction features |
IDE manages context |
| OS-level sandbox |
Seatbelt/bubblewrap |
Container-based |
IDE + cloud VM |
| Data residency |
Files stay in your perimeter |
Cloud sandbox (files on OpenAI infra) |
Cloud or local (user’s choice) |
The key differentiator for Anthropic is the self-hosted execution model. Both OpenAI and Cursor offer cloud execution (where files are processed on their infrastructure) and local options (where files stay on your machine). Anthropic splits the difference: the model’s reasoning runs on Anthropic’s cloud (giving access to Claude’s capabilities without local GPU requirements), but code execution — where sensitive data is actually touched — runs on your servers.
For enterprises where “data leaves our perimeter” is a hard compliance boundary, Anthropic’s model provides a middle ground that neither pure-cloud nor pure-local alternatives match. The model’s thinking uses Anthropic’s infrastructure (which you’re already trusting with your prompts), while your data stays behind your walls.
Frequently Asked Questions
Q: Does self-hosted sandbox execution cost more?
Anthropic hasn’t published specific pricing for self-hosted sandboxes. The sandbox compute resources (CPU, memory) are provided by your infrastructure, which you’re already paying for. Anthropic charges for the model usage (token-based) regardless of where execution happens. The cost difference is the infrastructure you provide vs. the infrastructure Anthropic would have provided.
Q: What are the minimum requirements for running a self-hosted sandbox?
The sandbox runs as a managed execution environment — you can use Cloudflare Workers, Vercel Functions, Daytona, Modal, or your own container infrastructure. The specific requirements depend on the provider: Cloudflare/Vercel require zero infrastructure management; on-prem requires Docker or similar container runtime with the Anthropic sandbox runtime installed.
Q: Can MCP tunnels work with on-prem databases behind a corporate proxy?
MCP tunnels initiate an outbound encrypted connection from inside your network. If your corporate proxy allows outbound connections (as most do), the tunnel works through it. The key property is that no inbound connections are required — the tunnel client connects out.
Q: How does mid-session tool swapping affect agent context?
The agent’s context adjusts dynamically — new tools appear in the tool list, removed tools disappear. The conversation history and task state are preserved. This is handled by the agent runtime, not the model — the model sees an updated tool list in the next turn.
Q: What happens if the self-hosted sandbox crashes mid-task?
The agent’s conversation state and task progress are maintained on Anthropic’s side (the orchestration layer). If the sandbox crashes, the agent can restart execution in a new sandbox — either resuming from a snapshot or restarting the current step. State loss depends on whether sandbox snapshots were configured.
Q: Is the MCP tunnel approach compatible with zero-trust architecture?
Yes. MCP tunnels follow zero-trust principles: outbound-only connections, encrypted end-to-end, per-session authentication, and no persistent network exposure. Each tunnel is scoped to a specific session and tool, not a persistent network bridge.
Glossary
-
Self-hosted sandbox: A code execution environment running on the customer’s infrastructure (or managed provider) rather than Anthropic’s cloud — files and data stay behind the customer’s firewall
-
MCP tunnel: An encrypted outbound connection from inside a private network to Claude Code, enabling tool access to internal services without inbound firewall rules
-
OS-level sandboxing: Filesystem and network isolation enforced by operating system primitives (Seatbelt on macOS, bubblewrap on Linux) rather than application-level controls
-
Mid-session tool swapping: The ability to add, remove, or modify agent tools and MCP server configurations during an active session without restarting
-
Context offloading: Automatically writing large tool outputs (100K+ tokens) to sandbox files instead of inserting them directly into the agent’s context window
Author
Ramsis Hammadi — AI/ML engineer specializing in GenAI, LLM engineering, and automation. Full bio →

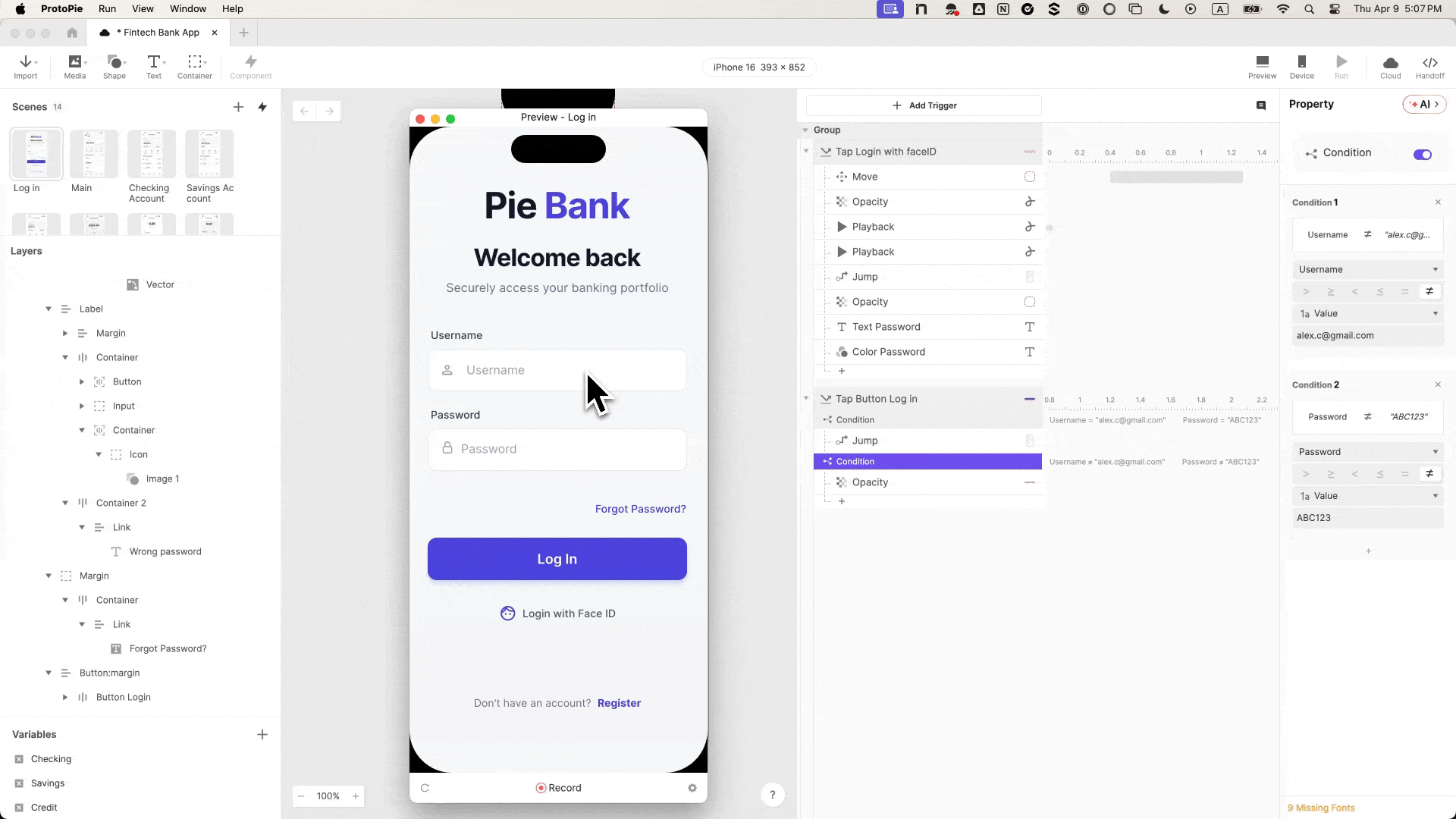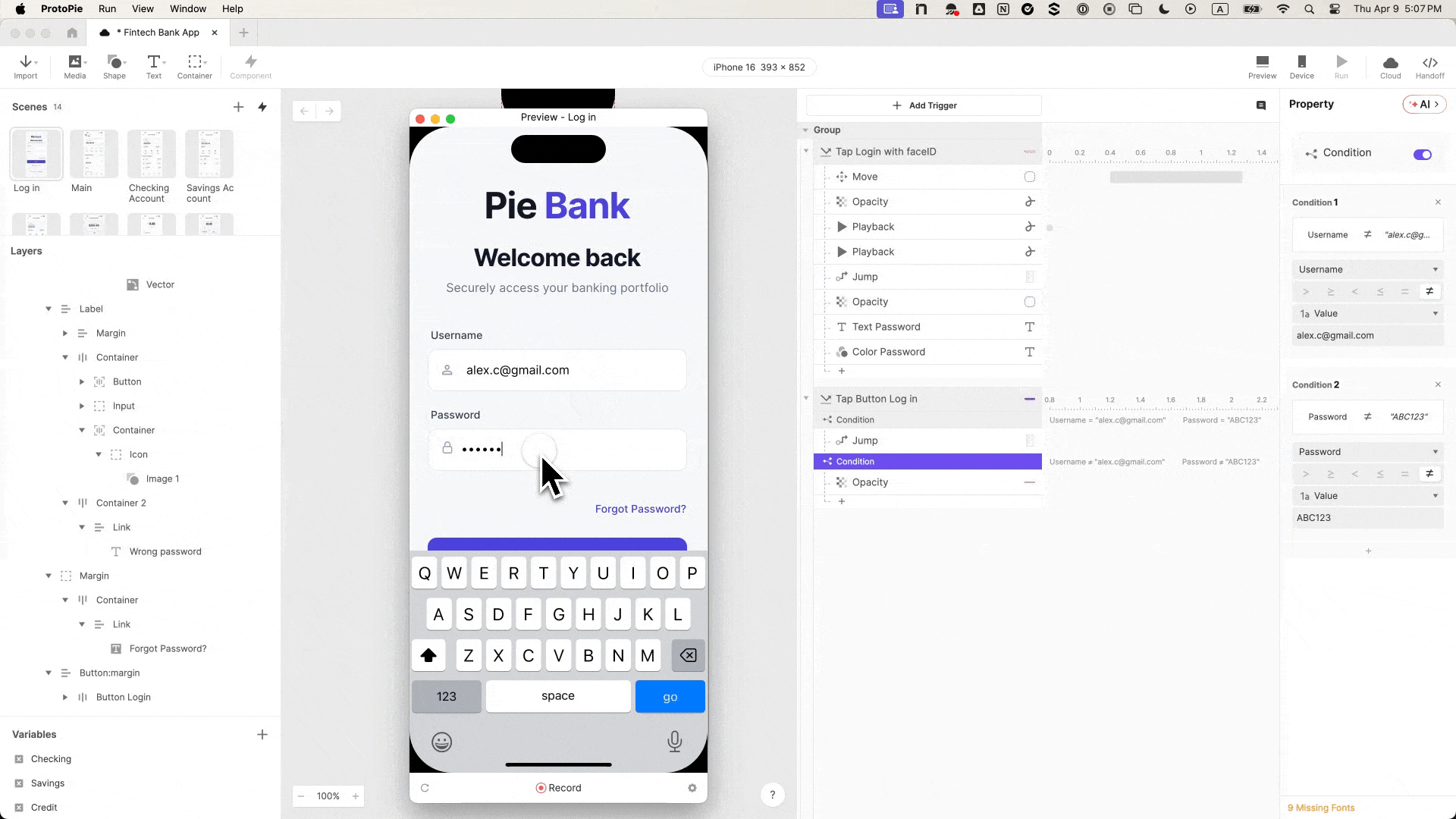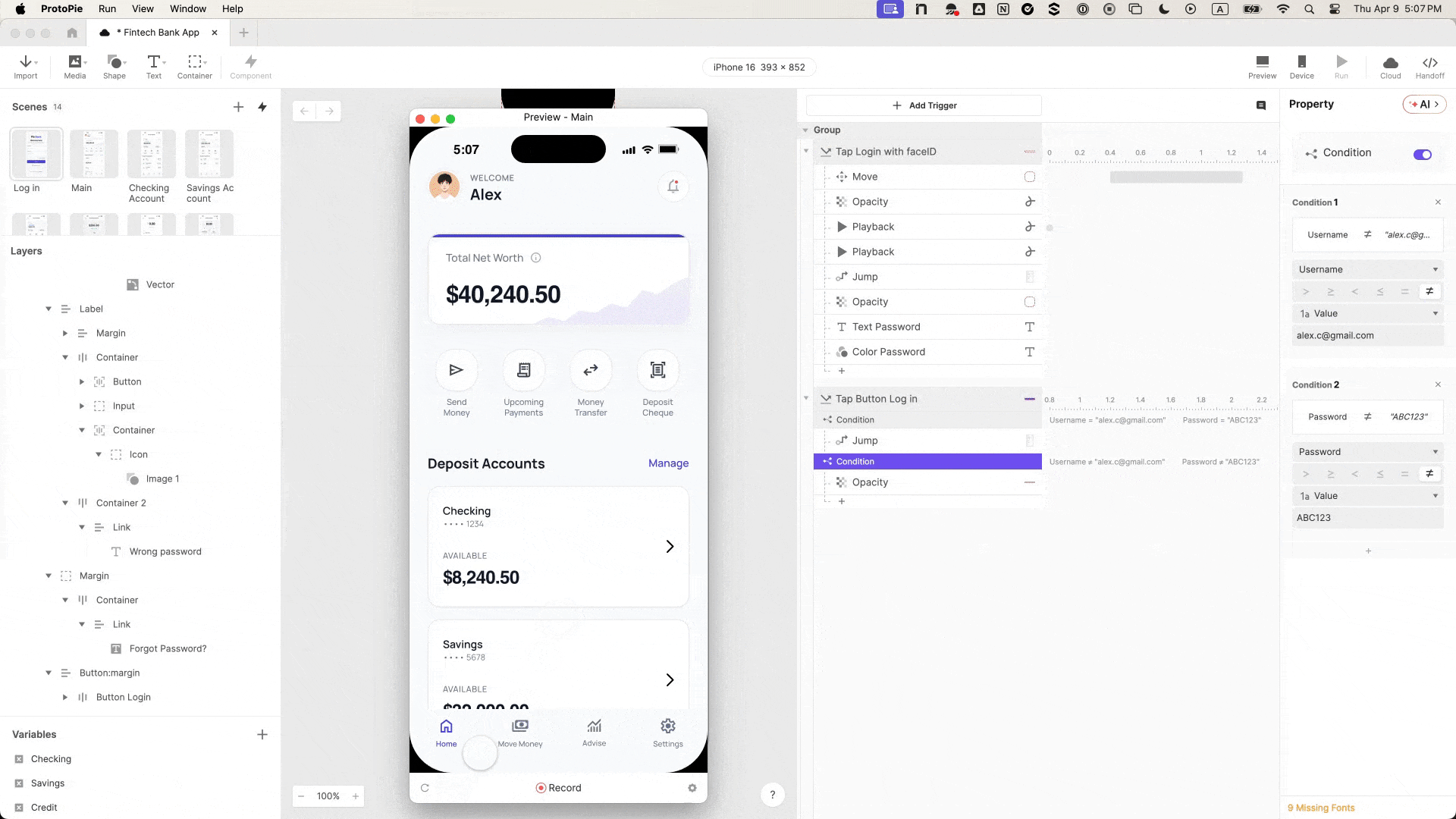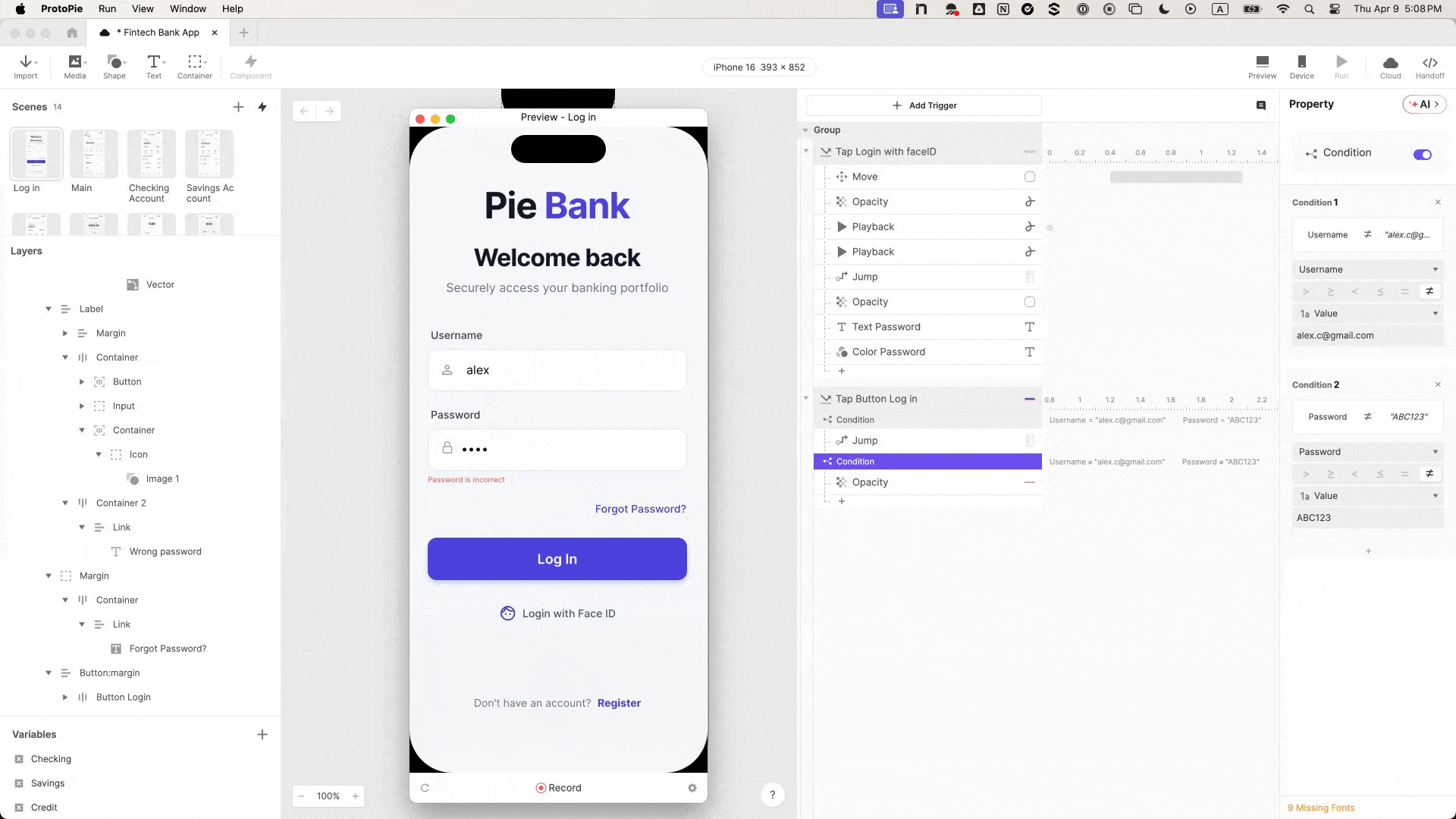
 You can download Pie Bank, Chapter 1: Login Flow and explore it freely.
You can download Pie Bank, Chapter 1: Login Flow and explore it freely.