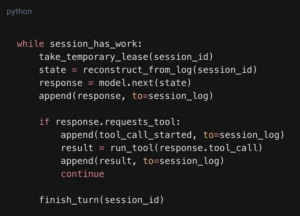
RAG for Code: Why Chunking by Function Beats Chunking by Lines

I built a retrieval system over a codebase so an LLM could answer questions about it, and my first version was nearly useless. The problem was not the model or the embeddings. It was how I cut the code…