
Everyone has a creative spark in them. Some bring their ideas to life with digital tools, others capture the perfect moment with a camera or love to grab pen and paper to create little doodles or pieces of lettering. And even if you don’t think of yourself as particularly creative, who knows? There might be a hidden talent waiting to be discovered!
That’s exactly what our monthly wallpapers series has been all about for over 15 years now. It’s a chance to step away from the everyday and dive into a fun, creative project. And this month is no different!
Talented artists and designers from all over the world have once again put their skills to work, creating unique and inspiring desktop wallpapers to brighten up your screens this June. You’ll find their designs below, along with some favorites from our archives that were just too good to leave out. A huge thank you to everyone who shared their creations with us this month — you’re smashing!
If you too would like to get featured in one of our upcoming wallpapers posts, please don’t hesitate to join in. We can’t wait to see what you’ll come up with! Happy June!
- You can click on every image to see a larger preview.
- We respect and carefully consider the ideas and motivation behind each and every artist’s work. This is why we give all artists the full freedom to explore their creativity and express emotions and experience through their works. This is also why the themes of the wallpapers weren’t anyhow influenced by us but rather designed from scratch by the artists themselves.
Drifting Into June
“June marks the beginning of summer and the end of the semester for many colleges. When I think of summer, I think of walks along the park with my family watching ducks swimming in the lake, and swimming in our pool with my siblings. Naturally from there I put them together to create an amusing scene of a duck slowly paddling around in an inner tube.” — Designed by Emma Kim from the United States.

- preview
- with calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Let The Ocean Influence You
“The ocean covers more than 70% of the surface of the Earth, yet we know barely anything about it. Maybe June can be the month you discover something new about yourself.” — Designed by Ginger IT Solutions from Serbia.

- preview
- with calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Dancing In The Kitchen
“June is such an iconic summer month, filled with sunshine, hope, and possibilities. When we raise both hands above our heads in celebratory dance, we symbolically release our cares for the day. When we do this dance in the kitchen, we not only release but also celebrate our bodies, our souls, and nourishment we’re about to give ourselves. This digital collage represents the freedom of movement, of dance, of joyful expression, of nourishment, creativity, and hope. May we all dance in the kitchen.” — Designed by Sue Jenkins from the United States.

- preview
- with calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Fruit & Gingham
“June reminds me of fresh fruit and bright colors, so I decided to watercolor some fruits, and it complimented well on a blue gingham picnic table background!” — Designed by Ella Peplowski from Ringwood, NJ.

- preview
- with calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Not In The Mood Forecast
Designed by Ricardo Gimenes from Spain.

- preview
- with calendar: 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440, 3840×2160
- without calendar: 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440, 3840×2160
Ballpark Patches
“June brings in warmer weather, so I designed a baseball-patch-inspired piece to celebrate the start of the season and the nice weather.” — Designed by Madison Evans from Scranton, PA.

- preview
- with calendar: 320×480, 640×480, 800×480, 1024×768, 1280×720, 1280×800, 1280×960, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
- without calendar: 320×480, 640×480, 800×480, 1024×768, 1280×720, 1280×800, 1280×960, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
A Very Special Amusement Park
“June brings summer, and it’s a great time to travel and experience new adventures! An amusement park is always a good idea, although some are best enjoyed from the comfort of your own home.” — Designed by Veronica Valenzuela from Spain.

- preview
- with calendar: 640×480, 800×480, 1024×768, 1280×720, 1280×800, 1440×900, 1600×1200, 1920×1080, 1920×1440, 2560×1440
- without calendar: 640×480, 800×480, 1024×768, 1280×720, 1280×800, 1440×900, 1600×1200, 1920×1080, 1920×1440, 2560×1440
Wavy Jellyfish
Designed by Jayden Evans from Scranton, Pennsylvania.

- preview
- with calendar: 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
- without calendar: 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Buzzing Through June
“I first found this color palette and thought it was very springy, and when I think of spring I think of flowers and bees. So I wanted to create a design that incorporated both in a cute way.” — Designed by Caroline Flynn from the United States.

- preview
- with calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1920×1080, 1920×1200, 1920×1440, 2560×1440
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Tiny Paradise Under the Sun
“Summer is hidden in the simple moments — the shimmer of crystal water, the warmth of the sun on your skin, and the calm sound of a peaceful afternoon. The warm wooden deck and soft shade of the parasol create a peaceful corner made for daydreaming. Flowers bloom, lemonade stays cold, and the sunlight dances across the pool like a golden melody. It’s the season of relaxation, happiness, and small moments that feel unforgettable.” — Designed by PopArt Studio from Novi Sad, Serbia.

- preview
- with calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Patches Of Flowers
“I wanted to make something in Blender, and once I made these flowers I felt like it needed something more, so I added more texture and more colors to make these flowers more peaceful.” — Designed by Caroline Flynn from the United States.
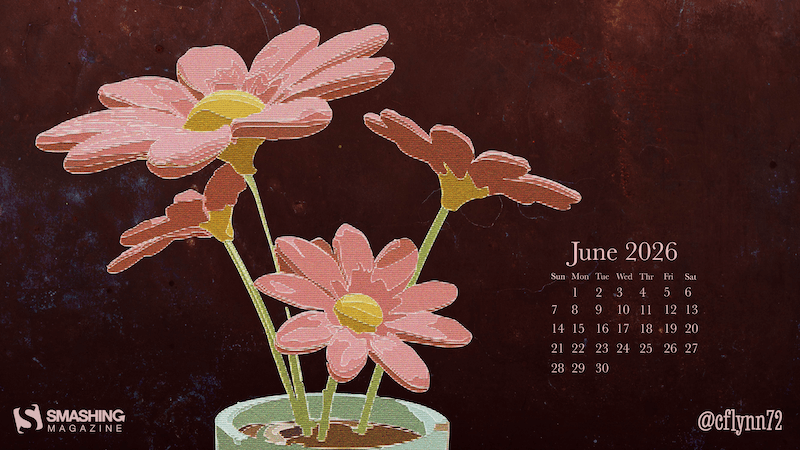
- preview
- with calendar: 320×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440
- without calendar: 320×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440
Amsterdam
“Inspired by the upcoming 2027 edition of SmashingConf Amsterdam.” — Designed by Ricardo Gimenes from Spain.

- preview
- with calendar: 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440, 3840×2160
- without calendar: 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440, 3840×2160
Let Me Grow With You
Designed by James Lucia from Covington Township, Pennsylvania.

- preview
- with calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440, 3840×2160
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440, 3840×2160
Travel Time
“June is our favorite time of the year because the keenly anticipated sunny weather inspires us to travel. Stuck at the airport, waiting for our flight but still excited about wayfaring, we often start dreaming about the new places we are going to visit. Where will you travel to this summer? Wherever you go, we wish you a pleasant journey!” — Designed by PopArt Studio from Serbia.
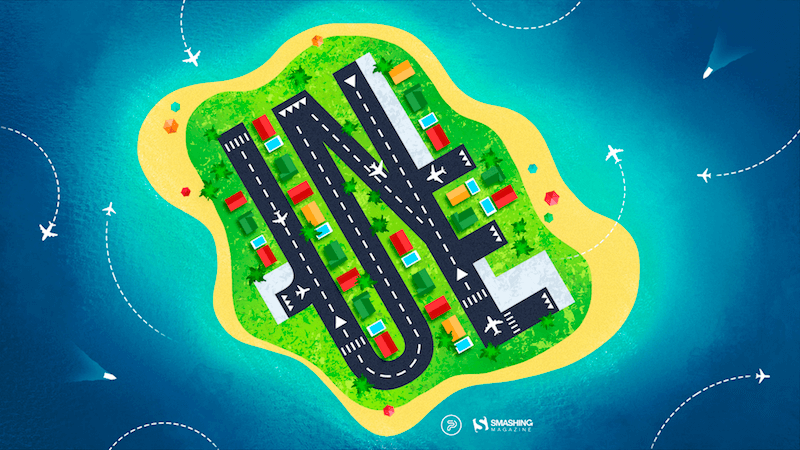
- preview
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
June Is For Nature
“In this illustration, Earth is planting a little tree — taking care, smiling, doing its part. It’s a reminder that even small acts make a difference. Since World Environment Day falls in June, there’s no better time to give back to the planet.” — Designed by Ginger IT Solutions from Serbia.

- preview
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1020, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Tastes Of June
“A vibrant June wallpaper featuring strawberries and fresh oranges, capturing the essence of early summer with bright colors and seasonal charm.” — Designed by Libra Fire from Serbia.

- preview
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
A Bibliophile’s Shelf
“Some of my favorite things to do are reading and listening to music. I know that there are a lot of people that also enjoy these hobbies, so I thought it would be a perfect thing to represent in my wallpaper.” — Designed by Cecelia Otis from the United States.

- preview
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1200, 1920×1440, 2560×1440
Here Comes The Sun
Designed by Ricardo Gimenes from Spain.

- preview
- without calendar: 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440, 3840×2160
Create Your Own Path
“Nice weather has arrived! Clean the dust off your bike and explore your hometown from a different angle! Invite a friend or loved one and share the joy of cycling. Whether you decide to go for a city ride or a ride in nature, the time spent on a bicycle will make you feel free and happy. So don’t wait, take your bike and call your loved one because happiness is greater only when it is shared. Happy World Bike Day!” — Designed by PopArt Studio from Serbia.

- preview
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Deep Dive
“Summer rains, sunny days, and a whole month to enjoy. Dive deep inside your passions and let them guide you.” — Designed by Ana Masnikosa from Belgrade, Serbia.

- preview
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Oh, The Places You Will Go!
“In celebration of high school and college graduates ready to make their way in the world!” — Designed by Bri Loesch from the United States.

- preview
- without calendar: 320×480, 1024×768, 1280×1024, 1440×900, 1680×1050, 1680×1200, 1920×1440, 2560×1440
Merry-Go-Round
Designed by Xenia Latii from Germany.

- preview
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Join The Wave
“The month of warmth and nice weather is finally here. We found inspiration in the World Oceans Day which occurs on June 8th and celebrates the wave of change worldwide. Join the wave and dive in!” — Designed by PopArt Studio from Serbia.

- preview
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Summer Surf
“Summer vibes…” — Designed by Antun Hirsman from Croatia.
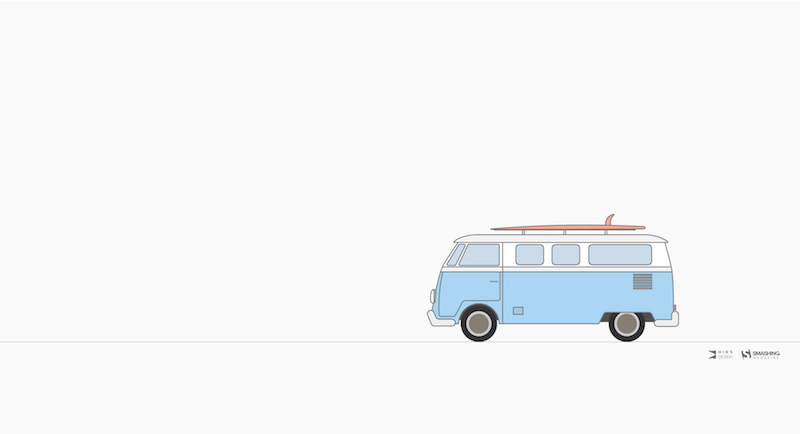
- preview
- without calendar: 640×480, 1152×864, 1280×1024, 1440×900, 1680×1050, 1920×1080, 1920×1440, 2650×1440
Summer Party
Designed by Ricardo Gimenes from Spain.

- preview
- without calendar: 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440, 3840×2160
Expand Your Horizons
“It’s summer! Go out, explore, expand your horizons!” — Designed by Dorvan Davoudi from Canada.

- preview
- without calendar: 800×480, 800×600, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Handmade Pony Gone Wild
“This piece was inspired by the My Little Pony cartoon series. Because those ponies irritated me so much as a kid, I always wanted to create a bad-ass pony.” — Designed by Zaheed Manuel from South Africa.

- preview
- without calendar: 800×600, 1024×768, 1280×960, 1280×1024, 1680×1050, 1920×1200, 2560×1440, 2880×1800
Pineapple Summer Pop
“I love creating fun and feminine illustrations and designs. I was inspired by juicy tropical pineapples to celebrate the start of summer.” — Designed by Brooke Glaser from Honolulu, Hawaii.

- preview
- without calendar: 640×480, 800×600, 1024×768, 1152×720, 1280×720, 1280×800, 1280×960, 1366×768, 1440×900, 1680×1050, 1920×1080, 1920×1200, 1920×1440, 2560×1440
All-Seeing Eye
Designed by Ricardo Gimenes from Spain.

- preview
- without calendar: 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440, 3840×2160
Nine Lives
“I grew up with cats around (and drawing them all the time). They are so funny… one moment they are being funny, the next they are reserved. If you have place in your life for a pet, adopt one today!” — Designed by Karen Frolo from the United States.
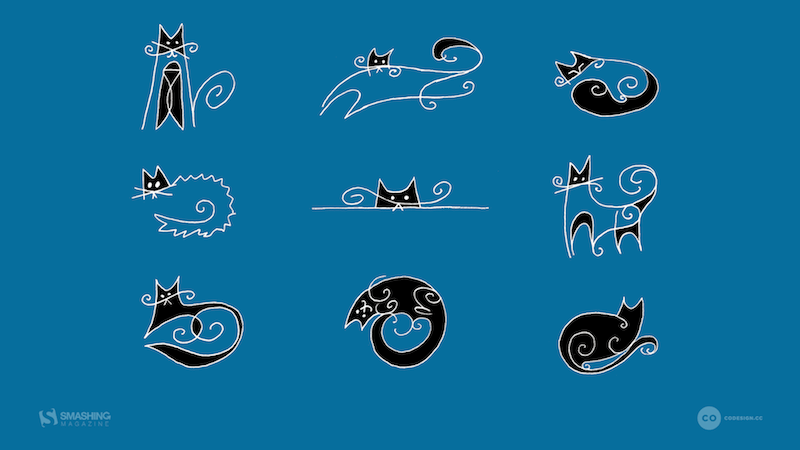
- preview
- without calendar: 1024×768, 1024×1024, 1280×800, 1280×960, 1280×1024, 1366×768, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Summer Coziness
“I’ve waited for this summer more than I waited for any other summer since I was a kid. I dream of watermelon, strawberries, and lots of colors.” — Designed by Kate Jameson from the United States.

- preview
- without calendar: 320×480, 1024×1024, 1280×720, 1680×1200, 1920×1080, 2560×1440
Bauhaus
“I created a screenprint of one of the most famous buildings from the Bauhaus architect Mies van der Rohe for you. So, enjoy the Barcelona Pavillon for your June wallpaper.” — Designed by Anne Korfmacher from Germany.

- preview
- without calendar: 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Strawberry Fields
Designed by Nathalie Ouederni from France.

- preview
- without calendar: 320×480, 1024×768, 1280×1024, 1440×900, 1680×1200, 1920×1200, 2560×1440
Papa Merman
“Dream away for a little while to a land where June never ends. Imagine the ocean, feel the joy of a happy and carefree life with a scent of shrimps and a sound of waves all year round. Welcome to the world of Papa Merman!” — Designed by GraphicMama from Bulgaria.

- preview
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Solstice Sunset
“June 21 marks the longest day of the year for the Northern Hemisphere — and sunsets like these will be getting earlier and earlier after that!” — Designed by James Mitchell from the United Kingdom.

- preview
- without calendar: 1280×720, 1280×800, 1366×768, 1440×900, 1680×1050, 1920×1080, 1920×1200, 2560×1440, 2880×1800
Getting Better Everyday
“Inspired by the eternal forward motion to get better and excel.” — Designed by Zachary Johnson-Medland from the United States.

- preview
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1366×768, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Reef Days
“June brings the start of summer full of bright colors, happy memories, and traveling. What better way to portray the goodness of summer than through an ocean folk art themed wallpaper. This statement wallpaper gives me feelings of summer and I hope to share that same feeling with others.” — Designed by Taylor Davidson from Kentucky.

- preview
- without calendar: 480×800, 1024×1024, 1242×2208, 1280×1024
Ice Creams Away!
“Summer is taking off with some magical ice cream hot air balloons.” — Designed by Sasha Endoh from Canada.
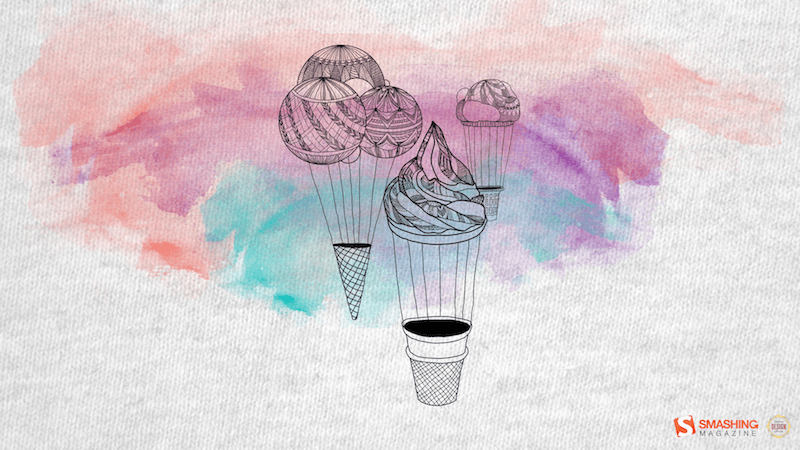
- preview
- without calendar: 320×480, 1024×768, 1152×864, 1280×800, 1280×960, 1400×1050, 1440×900, 1600×1200, 1680×1050, 1920×1080, 1920×1200, 2560×1440
Melting Away
Designed by Ricardo Gimenes from Spain.

- preview
- without calendar: 320×480, 640×480, 800×480, 800×600, 1024×768, 1024×1024, 1152×864, 1280×720, 1280×800, 1280×960, 1280×1024, 1400×1050, 1440×900, 1366×768, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Sunset With Crabs
“In the sunset, the crabs come to the surface. That little boat can’t sail, but after seeing the crabs it gets power and finally… it sails!” – Designed by Veronica Valenzuela from Spain.

- preview
- without calendar: 640×480, 800×480, 1024×768, 1280×720, 1280×800, 1440×900, 1600×1200, 1920×1080, 1920×1440, 2560×1440
World Environment Day
“On June 5th, we celebrate World Environment Day — a moment to pause and reflect on how we impact Earth’s health. A few activities represented in this visual include conserving energy and water, shopping and growing local, planting flowers and trees, and building a sustainable infrastructure.” — Designed by Mad Fish Digital from Portland, OR.

- preview
- without calendar: 320×480, 1024×1024, 1280×720, 1680×1200, 1920×1080, 2560×1440
Shine Your Light
“Shine your light, Before the fight, Just like the sun, Cause we don’t have to run.” — Designed by Anh Nguyet Tran from Vietnam.

- preview
- without calendar: 768×1280, 1024×1024, 1280×800, 1280×1024, 1366×768, 1440×900, 1600×1200, 1680×1050, 1680×1200, 1920×1080, 1920×1200, 1920×1440, 2560×1440
Get Featured Next Month
Feeling inspired? We’ll publish the July wallpapers on June 30, so if you’d like to be part of the collection, please don’t hesitate to submit your design. We are already looking forward to it!













 ted: the hardest part wasn’t the code. It was distilling 30 years of sales intuition into structured prompts.
ted: the hardest part wasn’t the code. It was distilling 30 years of sales intuition into structured prompts.