There’s a hypothesis that most people building AI agents have encountered but few have measured: the more tools you give an LLM, the worse it gets at picking the right one.
It’s intuitive. Connect a few MCP servers to your agent, and suddenly it’s choosing from 60, 80, 100+ tools. GitHub tools, GitLab tools, Kubernetes, Slack, Jira, PagerDuty, Terraform, Grafana, all loaded into the context window, all the time. The model has to read every tool definition, understand the distinctions between them, and pick the right one. That’s a lot of signal to sift through.
But intuition isn’t data. So we built Boundary, an open-source framework for finding where LLM context breaks, and ran the numbers.
The setup
We assembled 150 tool definitions based on real schemas from production agent systems across 16 services: GitHub, GitLab, Jira, Confluence, Kubernetes, AWS, Datadog, Slack, PagerDuty, Okta, Snyk, Grafana, Terraform Cloud, Docker, Linear, and Notion. The tools are synthetic (no-op for benchmarking) but the schemas, parameter structures, and descriptions mirror what you’d find in a production MCP environment.
We tested six models across three providers:
- Claude Sonnet 4.6 and Claude Haiku 4.5 (Anthropic)
- GPT-4o and GPT-5.4 Mini (OpenAI)
- Grok 4 and Grok 4.1 Fast Reasoning (xAI)
Each model received 60 prompts (both direct requests and ambiguous ones) at five toolset sizes: 25, 50, 75, 100, and 150 tools. At each size, the available tools were randomly selected but always included the correct one. The question: does the model pick the right tool?
The results
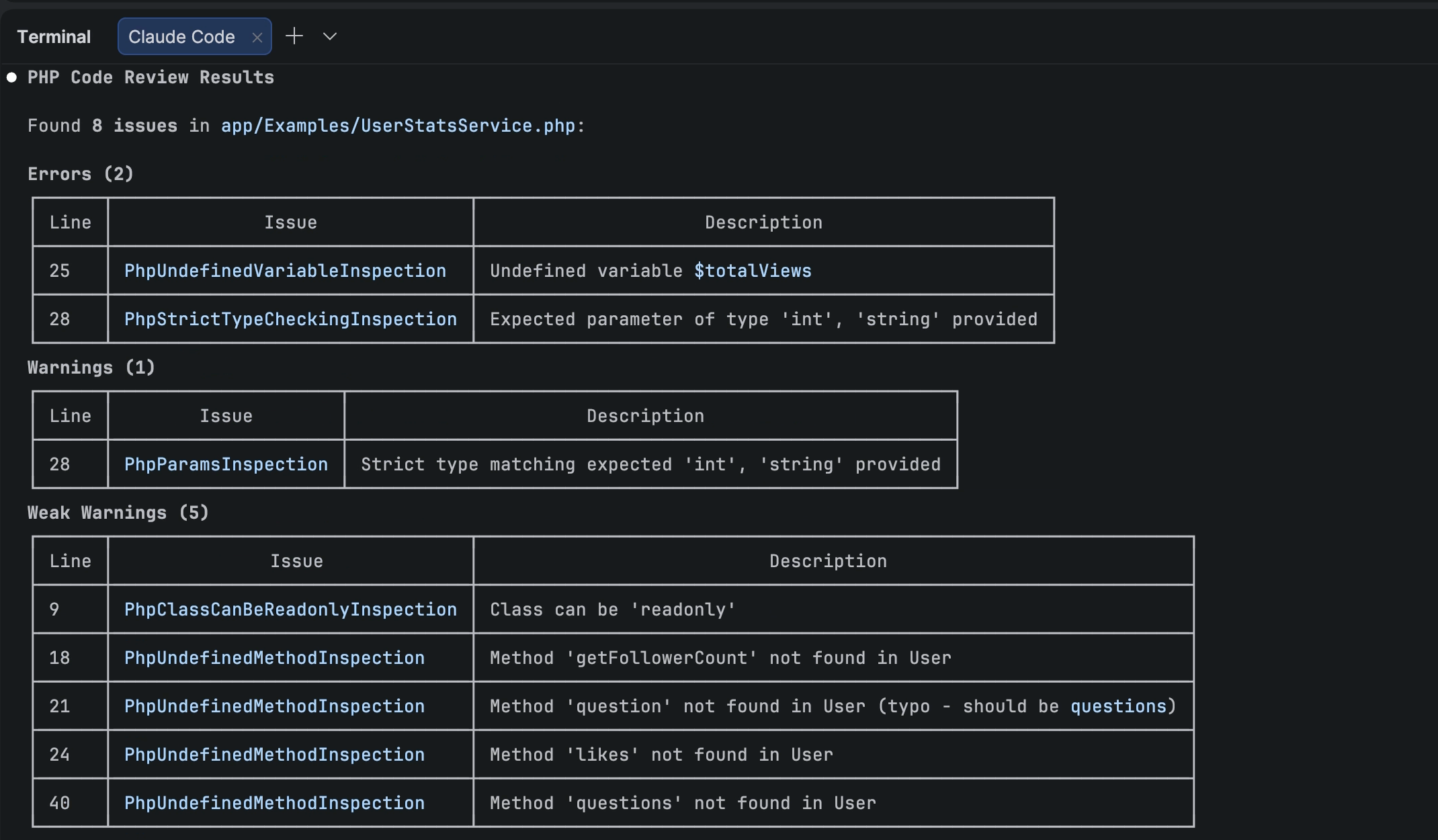
Every model that completed the test degraded. Two didn’t finish at all.
| Model | 25 tools | 50 tools | 75 tools | 100 tools | 150 tools |
|---|---|---|---|---|---|
| Grok 4.1 Fast | 86.7% | 83.3% | 80.0% | 83.3% | 76.7% |
| GPT-5.4 Mini | 85.0% | 85.0% | 80.0% | 83.3% | failed |
| GPT-4o | 81.7% | 78.3% | 73.3% | 76.7% | failed |
| Claude Haiku 4.5 | 81.7% | 80.0% | 78.3% | 80.0% | 76.7% |
| Grok 4 | 80.0% | 78.3% | 80.0% | 71.7% | 80.0% |
| Claude Sonnet 4.6 | 78.3% | 73.3% | 73.3% | 76.7% | 75.0% |

GPT-5.4 Mini was the most surprising result. At 85% accuracy through 50 tools, 92% on ambiguous prompts, sub-1-second latency, and $0.002 per call, it was arguably the best overall performer for small-to-medium toolsets. Then it hit the same 128-tool wall as GPT-4o and failed completely at 150.
Grok 4.1 Fast Reasoning was the only model that combined top-tier accuracy with the ability to handle 150 tools. It degraded steadily from 86.7% to 76.7%, but it never broke.
Both OpenAI models failed at 150 tools. OpenAI’s API has a hard limit of 128 tools per request. This isn’t a degradation curve. It’s a wall. If your agent connects enough MCP servers to exceed 128 tools, no OpenAI model works.
Claude Sonnet 4.6, the most expensive model in the test ($0.028/call), was the least accurate at 25 tools and never recovered. Claude Haiku outperformed it at every size while costing 3x less.
Cross-service confusion scales with tools
Cross-service confusion, where a model picks a tool from the wrong service entirely, was the most dangerous failure mode.
| Model | 25 tools | 50 tools | 75 tools | 100 tools | 150 tools |
|---|---|---|---|---|---|
| Claude Haiku 4.5 | 0 | 0 | 1 | 2 | 4 |
| Grok 4.1 Fast | 0 | 0 | 0 | 2 | 3 |
| Claude Sonnet 4.6 | 0 | 1 | 2 | 3 | 2 |
| Grok 4 | 2 | 0 | 2 | 4 | 1 |
| GPT-4o | 0 | 0 | 1 | 2 | n/a |
| GPT-5.4 Mini | 0 | 0 | 2 | 1 | n/a |
Grok 4 had cross-service errors even at 25 tools. Claude Haiku was clean until 75 tools but escalated to 4 errors at 150, the worst of any model at that size.
The most common cross-service confusions across all models:
- Datadog vs Grafana: “Check the monitoring alerts” consistently routed to the wrong observability platform
- Notion vs Confluence: “Search for documentation” split between the two
- Linear vs Jira: “Add a comment to the tracking issue” picked the wrong project tracker
- GitHub vs GitLab: “Show me the open issues” confused the two at higher tool counts
Direct vs. ambiguous prompts
A “direct” prompt names the service: “List all Terraform Cloud workspaces.” An “ambiguous” prompt doesn’t: “Add a comment saying ‘Resolved’ to the tracking issue.”
| Model | 25t (ambig) | 50t (ambig) | 75t (ambig) | 100t (ambig) | 150t (ambig) |
|---|---|---|---|---|---|
| GPT-5.4 Mini | 92% | 92% | 67% | 92% | n/a |
| Grok 4.1 Fast | 83% | 83% | 83% | 75% | 67% |
| Claude Sonnet 4.6 | 83% | 75% | 75% | 83% | 75% |
| GPT-4o | 83% | 83% | 67% | 58% | n/a |
| Claude Haiku 4.5 | 75% | 75% | 83% | 67% | 67% |
| Grok 4 | 67% | 75% | 67% | 50% | 67% |
GPT-5.4 Mini dominated ambiguous prompts at 92% through 100 tools. It handled disambiguation better than any other model by a wide margin. GPT-4o collapsed to 58% at the same size. Grok 4 hit 50%, a coin flip.
Claude Sonnet was the most stable, staying between 75% and 83% regardless of toolset size. Consistent, but never great.
Where models get confused
The errors tell a story. Some patterns appeared across all six models:
Terraform is hard. All models consistently confused terraform_create_run with terraform_list_workspaces, and terraform_lock_workspace with terraform_get_workspace. The tool names are semantically close, and the models default to “list” or “get” operations when the toolset is crowded.
Snyk is a trap. snyk_get_remediation, snyk_list_container_projects, and snyk_list_projects all got misrouted to snyk_list_organizations. When Snyk tools are buried among 100+ others, the models default to the most generic-sounding option.
Confluence updates fail. All models picked confluence_search when asked to update a page. The prompt said “Update the runbook page”, but with 75+ tools in context, the model reached for search instead of the update operation.
Monitoring platform confusion. Datadog and Grafana both have alerting, dashboards, and metrics tools. The prompt “Check the monitoring alerts for the API server” got routed to Grafana instead of Datadog by every model at some toolset size. Adding two similar services to the toolset creates permanent ambiguity.
The latency story
Accuracy isn’t the only cost.
| Model | 25 tools | 50 tools | 75 tools | 100 tools | 150 tools |
|---|---|---|---|---|---|
| GPT-5.4 Mini | 739ms | 754ms | 849ms | 976ms | n/a |
| GPT-4o | 1,170ms | 4,035ms | 6,213ms | 7,657ms | n/a |
| Claude Haiku 4.5 | 2,463ms | 6,157ms | 8,765ms | 11,473ms | 16,749ms |
| Claude Sonnet 4.6 | 4,728ms | 10,308ms | 14,579ms | 19,120ms | 27,935ms |
| Grok 4.1 Fast | 6,448ms | 7,042ms | 6,930ms | 7,349ms | 7,533ms |
| Grok 4 | 7,706ms | 7,945ms | 8,133ms | 8,418ms | 9,552ms |

GPT-5.4 Mini was the latency champion: sub-1-second at every toolset size it completed. The Anthropic models scaled linearly, with Sonnet reaching 28 seconds at 150 tools. The xAI models barely changed, staying in the 6-10 second range regardless of tool count.
What this means
The pattern is consistent across six models from three providers: more tools means worse accuracy, and the degradation starts between 25 and 50 tools.
The implications for anyone building agents with MCP:
-
Don’t load everything. If your agent has access to 10+ services, that’s easily 80-150 tools. Loading them all upfront is a measurable tax on accuracy, starting at 25 tools.
-
OpenAI has a hard wall at 128 tools. Both GPT-4o and GPT-5.4 Mini failed at 150. This isn’t a model quality issue. It’s a platform constraint. If your agent might exceed 128 tools, OpenAI models are not an option.
-
Ambiguous prompts are the danger zone. Grok 4 hit 50% accuracy on ambiguous prompts at 100 tools. GPT-4o dropped to 58%. When users don’t name the service explicitly, the model has to disambiguate, and more tools makes that exponentially harder.
-
Similar services compound the problem. Datadog and Grafana. Notion and Confluence. Linear and Jira. GitHub and GitLab. Every pair of similar services in the toolset creates a permanent source of confusion that scales with tool count.
-
Latency compounds. Even if accuracy were flat, the latency cost matters. Claude Sonnet at 28 seconds per call is unusable for interactive workloads. GPT-5.4 Mini at sub-1-second is a different product entirely.
-
Price does not predict performance. Claude Sonnet 4.6 costs 28x more per call than Grok 4.1 Fast and is less accurate. Claude Haiku outperforms Claude Sonnet at 3x lower cost. The most expensive model lost.
The cost equation
What you pay per call versus what you get in accuracy.
| Model | Total cost | Calls | Cost/call | Best accuracy | Worst accuracy |
|---|---|---|---|---|---|
| Grok 4.1 Fast | $0.31 | 300 | $0.0010 | 86.7% (25t) | 76.7% (150t) |
| GPT-5.4 Mini | $0.50 | 240* | $0.0021 | 85.0% (25t) | failed (150t) |
| GPT-4o | $1.57 | 240* | $0.0065 | 81.7% (25t) | failed (150t) |
| Claude Haiku 4.5 | $2.83 | 300 | $0.0094 | 81.7% (25t) | 76.7% (150t) |
| Grok 4 | $3.85 | 300 | $0.013 | 80.0% (25t) | 71.7% (100t) |
| Claude Sonnet 4.6 | $8.51 | 300 | $0.028 | 78.3% (25t) | 73.3% (50t) |
*OpenAI models completed 240 of 300 calls. All calls at 150 tools failed due to the 128-tool API limit.

The two cheapest models (Grok 4.1 Fast at $0.001/call and GPT-5.4 Mini at $0.002/call) were also the two most accurate. The most expensive model (Claude Sonnet at $0.028/call) was the least accurate. The correlation between price and tool-calling performance is not just weak. It’s inverted.
This is exactly the kind of tradeoff Boundary is designed to surface. Without benchmark data, you’d likely pick Claude Sonnet or GPT-4o. The data says they’re among the worst choices for tool-calling workloads. A team running fewer than 128 tools should seriously consider GPT-5.4 Mini for its combination of accuracy, speed, and cost. A team that might exceed 128 needs Grok 4.1 Fast or an Anthropic model.
Running these benchmarks costs almost nothing. This entire run across six models cost $17. That’s less than a single hour of engineer time debugging a misrouted tool call in production.
How this shaped our architecture
This data isn’t theoretical for us. It directly informed how we built progressive disclosure in SixDegree.
The core insight: if accuracy degrades between 25 and 50 tools, then the goal isn’t to find a smarter model. It’s to never present more than 25 tools in the first place. Not by hardcoding a curated list, but by letting the agent’s context determine which tools are relevant at each step.
In SixDegree, when an agent queries the ontology and discovers a GitHub repository, only the GitHub tools become available. When a Kubernetes deployment surfaces through a relationship, the Kubernetes tools appear. The agent never sees all 150 tools at once because it never needs to. The toolset at any given turn is scoped to the entities the agent has actually encountered.
The Boundary data validates this approach quantitatively. At 25 tools (roughly the size of two or three services’ worth of tools), accuracy is in the mid-to-high 80s. That’s the operating range progressive disclosure keeps you in, regardless of how many total services are connected. You can have 16 integrations and 150 tools installed, and the agent still only sees the 10-20 that matter for the current conversation.
The alternative, loading everything and hoping the model figures it out, costs you 5-10 percentage points of accuracy, up to 28x the latency, and for OpenAI models, a hard failure at 128 tools. Progressive disclosure isn’t a nice-to-have. It’s a requirement for agents that work at scale.
Limitations and what we’d like to improve
This benchmark is a starting point, not a definitive answer. There are real limitations to what it measures and how:
Single-turn only. Each prompt gets one shot at picking a tool. Real agents chain tool calls, use results from previous calls to inform the next one, and recover from mistakes. A model that picks the wrong tool on the first try might self-correct on a second turn. This benchmark doesn’t capture that.
Random tool subsets. At each toolset size, the available tools are randomly selected (with the correct one always included). In production, the tools in context aren’t random. They’re usually grouped by service or use case. Random selection may overstate or understate confusion depending on which tools end up adjacent.
No parameter validation. We check whether the model picked the right tool, but not whether it filled in the parameters correctly. A model that picks github_create_issue but hallucinates the owner field is still counted as correct. Parameter accuracy is a whole separate dimension.
Prompt quality varies. Some of the ambiguous prompts have arguably debatable expected answers. “Check the monitoring alerts” could reasonably map to either Datadog or Grafana depending on the organization. We picked one, but reasonable people would disagree.
Single trial. Each prompt runs once per toolset size. With 60 prompts per size, the results are directional but individual percentage points could shift with more trials.
We’d like to add multi-turn evaluation, parameter accuracy checking, configurable prompt difficulty levels, and more models. If you have ideas for how to make this benchmark better, if you disagree with our methodology, or if you’ve run Boundary against a model we haven’t tested yet, open an issue or submit a PR. This is an open source project and we want the community to help shape it.
What’s next
The full interactive results from this run are available on our site. The framework is open source. Run it yourself and see how your preferred models handle tool overload.
Boundary is an open-source framework for finding where LLM context breaks. See how SixDegree solves tool overload.