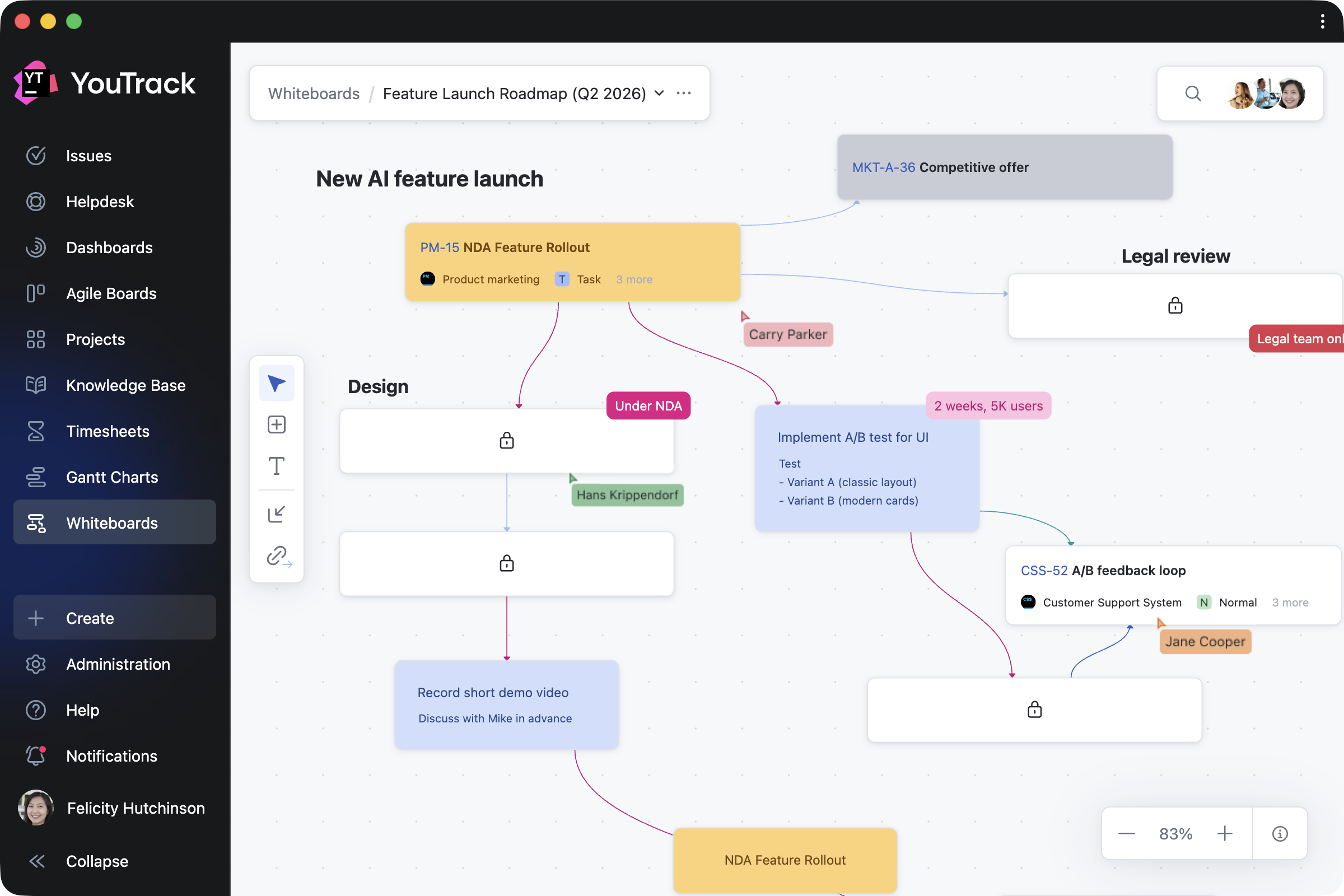
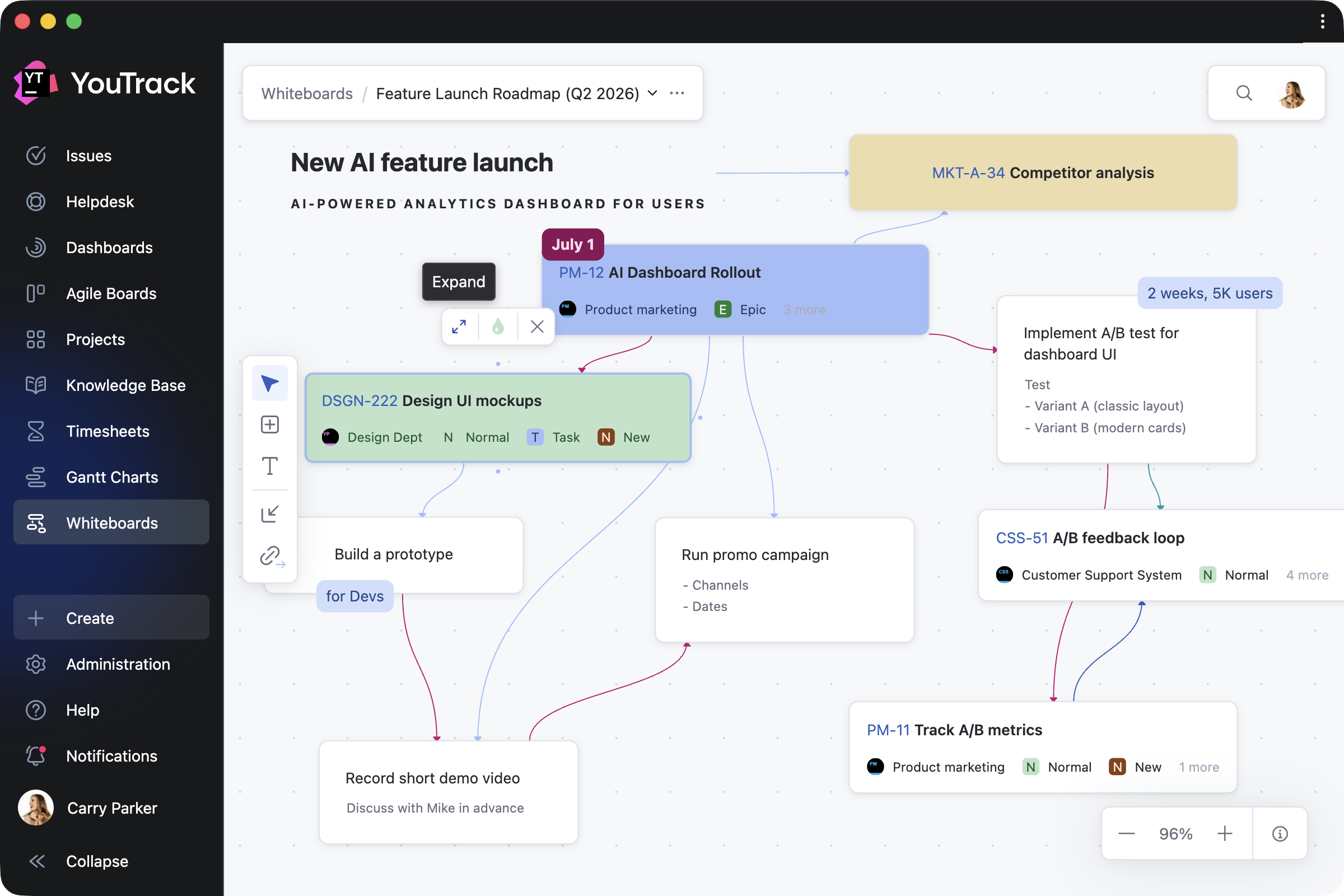
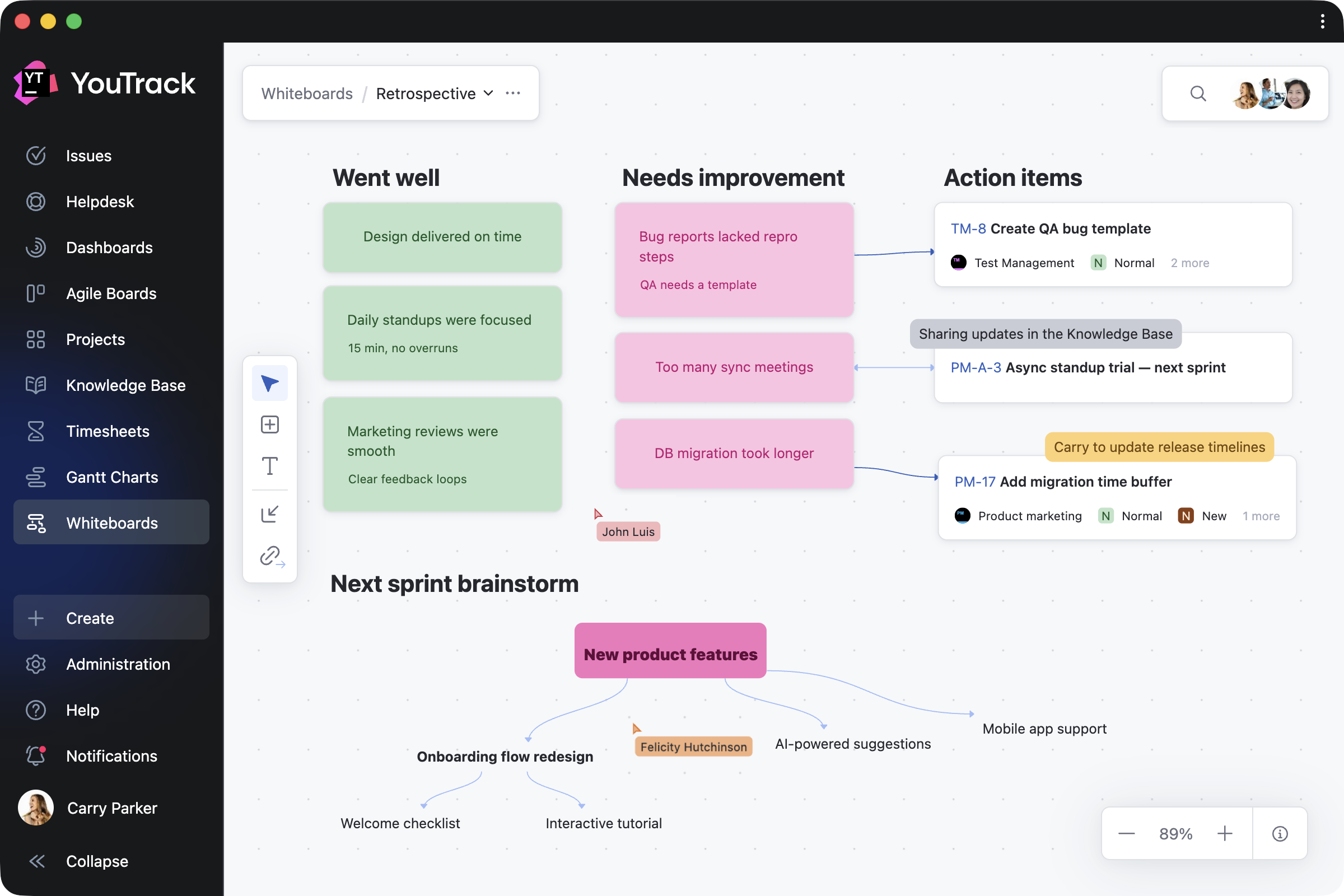
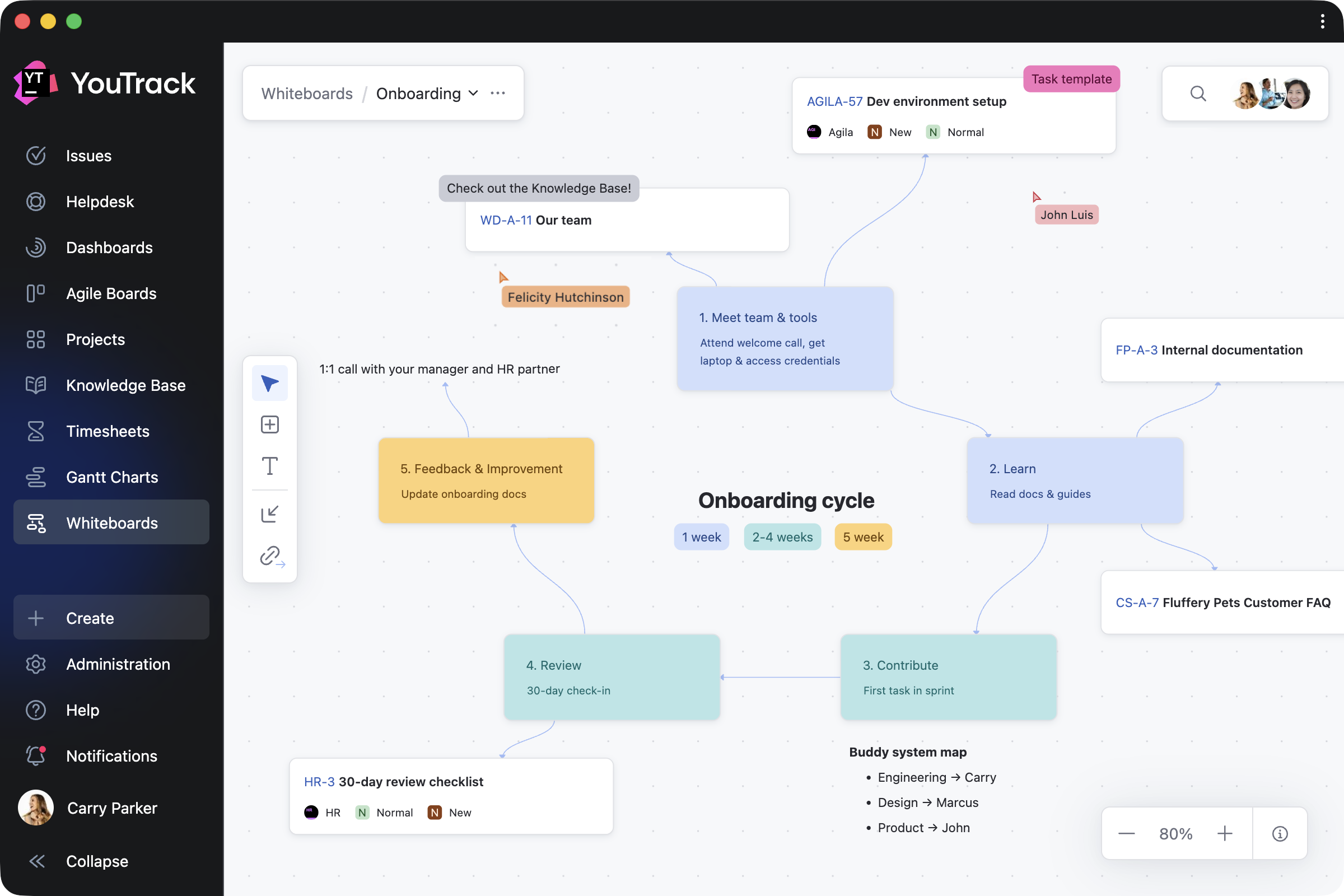
Docker has become the standard way to self-host n8n — and for good reason. But here’s what most tutorials don’t tell you: Docker makes n8n easier to run, but not necessarily easier to set up correctly. The gap between “Docker is running” and “n8n is working securely with HTTPS and persistent data” is where most people get stuck.
This article walks through the five most common failure points — and how to fix each one.
Key Takeaways (30-Second Summary)
- Docker is the standard way to self-host n8n, but setup is fraught with hidden pitfalls.
- The top 5 failure points are: SSL certificate configuration, environment variable typos, database persistence, update chaos, and port conflicts.
- Most “it doesn’t work” moments trace back to one of five specific misconfigurations.
- A working production setup requires proper SSL, reverse proxy, persistent volumes, and the right environment variables.
- The easier alternative: deploy n8n in 3 minutes on Agntable with everything pre-configured — no terminal, no debugging.
Why Docker for n8n?
Instead of installing n8n directly on your server (which requires manually setting up Node.js, managing dependencies, and dealing with version conflicts), Docker packages everything n8n needs into a single, isolated container. This approach offers several advantages:
- Isolation: n8n runs in its own environment, separate from other applications on your server.
- Portability: You can move your entire n8n setup to another server with minimal effort.
- Simplified updates: Upgrading n8n is often just a single command.
- Consistency: The same configuration works across development and production.
The official n8n documentation recommends Docker for self-hosting, and most tutorials follow this approach.
But “running” isn’t the same as “production-ready.”
The Real Problem: Why n8n Docker Setups Break
The real problems emerge when you try to:
- Access n8n securely over HTTPS
- Keep your data when the container restarts
- Configure n8n for your specific needs
- Update to a newer version without breaking everything
- Connect to external services that require custom certificates
One developer documented their painful update experience: “I broke everything trying to update n8n. Multiple docker-compose.yml files in different folders, outdated images tagged as <none>, conflicts between different image registries, containers running from different images than I thought.”
This isn’t an isolated story.
Failure Point #1: The SSL Certificate Maze
Symptom: You visit your n8n instance and see “Not Secure” in the browser, or worse — you can’t access it at all. Webhooks fail. You see ERR_CERT_AUTHORITY_INVALID or “secure cookie” warnings.
Why it happens: n8n requires HTTPS to function properly — especially for webhooks. But setting up SSL with Docker is surprisingly complex:
- You need a domain name pointed to your server.
- You need a reverse proxy (Nginx, Caddy, or Traefik) to handle HTTPS traffic.
- You need Let’s Encrypt certificates configured and set to auto-renew.
- You need to configure the reverse proxy to forward traffic to the n8n container.
- You need to ensure WebSocket connections work for the n8n editor.
The fix: A proper reverse proxy setup with correct headers.
server {
listen 443 ssl;
server_name n8n.yourdomain.com;
ssl_certificate /etc/letsencrypt/live/n8n.yourdomain.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/n8n.yourdomain.com/privkey.pem;
location / {
proxy_pass http://localhost:5678;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# WebSocket support (critical for n8n editor)
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
server {
listen 80;
server_name n8n.yourdomain.com;
return 301 https://$host$request_uri;
}
Even with this configuration, you still need to ensure the certificates renew automatically and that your firewall allows traffic on ports 80 and 443.
Failure Point #2: Environment Variable Hell
Symptom: n8n starts but behaves strangely. Webhooks don’t work. Authentication fails. Or n8n won’t start at all, with cryptic error messages.
Why it happens: n8n relies heavily on environment variables for configuration. A single typo — or missing variable — can break critical functionality.
| Variable | Purpose | Common Mistake |
|---|---|---|
N8N_HOST |
Defines the hostname n8n runs on | Setting to localhost instead of your actual domain |
N8N_PROTOCOL |
HTTP or HTTPS | Forgetting to set to https when using SSL |
WEBHOOK_URL |
Public URL for webhooks | Not setting this, causing webhook failures |
N8N_ENCRYPTION_KEY |
Encrypts credentials in the database | Using a weak key or not setting it at all |
DB_TYPE |
Database type (sqlite/postgresdb) | Not set for production use |
The fix: Use a .env file to manage variables cleanly.
# Domain configuration
N8N_HOST=n8n.yourdomain.com
N8N_PROTOCOL=https
WEBHOOK_URL=https://n8n.yourdomain.com/
# Security
N8N_ENCRYPTION_KEY=your-base64-32-char-key-here # openssl rand -base64 32
N8N_BASIC_AUTH_ACTIVE=true
N8N_BASIC_AUTH_USER=admin
N8N_BASIC_AUTH_PASSWORD=your-secure-password
# Database (PostgreSQL for production)
DB_TYPE=postgresdb
DB_POSTGRESDB_HOST=postgres
DB_POSTGRESDB_PORT=5432
DB_POSTGRESDB_USER=n8n
DB_POSTGRESDB_PASSWORD=your-db-password
DB_POSTGRESDB_DATABASE=n8n
# Timezone
GENERIC_TIMEZONE=America/New_York
Then reference this file in your docker-compose.yml using the env_file directive.
Failure Point #3: Database & Data Persistence Pitfalls
Symptom: You restart your n8n container, and all your workflows disappear. Or n8n crashes with database errors.
Why it happens: By default, n8n stores data inside the container. When the container is removed (during updates or restarts), that data vanishes. This is the number one data loss scenario for new n8n users.
The official n8n Docker documentation warns: if you don’t manually configure a mounted directory, all data (including database.sqlite) will be stored inside the container and will be completely lost once the container is deleted or rebuilt.
Even when you configure persistent volumes, permission issues can arise. The n8n container runs as user ID 1000, so the mounted directory must be writable by that user:
sudo chown -R 1000:1000 ./n8n-data
For production workloads, SQLite has limitations with concurrent writes. Use PostgreSQL.
The fix:
version: '3.8'
services:
postgres:
image: postgres:15-alpine
restart: unless-stopped
environment:
- POSTGRES_USER=n8n
- POSTGRES_PASSWORD=${DB_POSTGRESDB_PASSWORD}
- POSTGRES_DB=n8n
volumes:
- ./postgres-data:/var/lib/postgresql/data
networks:
- n8n-network
healthcheck:
test: ["CMD-SHELL", "pg_isready -U n8n"]
interval: 30s
timeout: 10s
retries: 5
n8n:
image: n8nio/n8n:latest
restart: unless-stopped
ports:
- "127.0.0.1:5678:5678"
env_file:
- .env
volumes:
- ./n8n-data:/home/node/.n8n
networks:
- n8n-network
depends_on:
postgres:
condition: service_healthy
networks:
n8n-network:
driver: bridge
Failure Point #4: The Update Nightmare
Symptom: You run docker compose pull && docker compose up -d to update n8n, and suddenly nothing works.
Why it happens: Several things can go wrong simultaneously:
- Wrong directory: You run the update command in the wrong folder.
-
Image registry confusion: Multiple n8n image sources exist (
n8nio/n8nvsdocker.n8n.io/n8nio/n8n). -
Stale images: Old images tagged as
<none>cause confusion. - Orphaned containers: Previous containers still running on old images.
- Database migrations: New n8n versions may require schema updates that don’t run automatically.
The fix: A safe update script.
#!/bin/bash
# update-n8n.sh - Safe update script
echo "📦 Backing up n8n data..."
tar -czf "n8n-backup-$(date +%Y%m%d-%H%M%S).tar.gz" ./n8n-data ./postgres-data
echo "🔄 Pulling latest images..."
docker compose pull
echo "🔄 Recreating containers..."
docker compose down
docker compose up -d --force-recreate
echo "✅ Update complete. Check logs: docker compose logs -f"
Always test updates in a staging environment first.
Failure Point #5: Port & Network Conflicts
Symptom: The n8n container starts, but you can’t access it. Or another application stops working.
Why it happens: The classic port mapping 5678:5678 exposes n8n directly on your server’s public IP. This creates port conflicts, a security risk, and no clean upgrade path to HTTPS.
The fix: Only expose n8n locally, then use a reverse proxy for external access:
ports:
- "127.0.0.1:5678:5678" # Only accessible from the same machine
The Working Production Setup
Here’s a complete directory structure for a production-ready n8n deployment:
n8n-docker/
├── .env # Environment variables (keep secure!)
├── docker-compose.yml # Service configuration
├── n8n-data/ # n8n persistent data (chown 1000:1000)
├── postgres-data/ # PostgreSQL persistent data
└── backups/ # Automated backups
Combine all the fixes above: the .env file from Failure Point #2, the docker-compose.yml from Failure Point #3, and the Nginx config from Failure Point #1. That’s a production-grade setup.
Frequently Asked Questions
What’s the minimum server spec for n8n with Docker?
n8n officially recommends a minimum of 2GB RAM and 1 vCPU for production use.
Can I use SQLite for production?
Technically yes, but it’s not recommended. SQLite’s concurrency limitations cause issues with multiple simultaneous workflow executions.
How do I fix permission issues with mounted volumes?
The n8n container runs as user ID 1000. Run sudo chown -R 1000:1000 ./n8n-data.
What environment variables are essential for HTTPS?
You must set N8N_PROTOCOL=https and WEBHOOK_URL=https://yourdomain.com/ (with trailing slash). Also ensure N8N_HOST matches your domain.
How often should I update n8n?
At least monthly for security reasons. Always back up before updating.
The Easier Alternative
After reading through all these failure points, you might be thinking: there has to be a better way.
Agntable was built specifically to solve these exact problems — SSL configuration, environment variables, database persistence, updates, and monitoring — handled automatically. Deploy n8n in 3 minutes with a live HTTPS URL, pre-configured PostgreSQL, daily verified backups, and 24/7 monitoring.
| What You Get | DIY Docker | Agntable |
|---|---|---|
| Setup time | 5–24 hours | 3 minutes |
| SSL configuration | Manual, error-prone | Automatic |
| Database | You configure | PostgreSQL pre-optimised |
| Backups | You script | Daily, verified |
| Updates | Manual, risky | Automatic, tested |
| Monitoring | You set up | 24/7 with auto-recovery |
| Monthly cost (including your time) | $150–$500+ | $9.99–$49.99 flat |
Conclusion: Build Workflows, Not Infrastructure
The Docker setup for n8n is a classic open-source trade-off: incredible power and flexibility, but significant operational complexity. If you’re a developer who enjoys infrastructure work, the DIY route can be rewarding. But if you want to build workflows rather than become a part-time sysadmin, there’s a better path.
Originally published on Agntable